Most query systems are oriented toward retrieving small data entries, not generating statistics on the database as a whole
Example: NCBI Entrez
Retrieve sequence entries based on BLAST scores
Retrieve sequence entries based on keyword search
What we need is a way to run through large sections of a database, and tabulate statistics. For example:
What is the distribution of sequence lengths reported for plants?
Are some plant species overrepresented, and others underrepresented in the databases?
For
a given gene family, is the representation of genes in genomic
sequences similar to that in EST populations (ie. bias toward strongly
expressed genes)?
Are certain categories of genes reported more frequently than others?
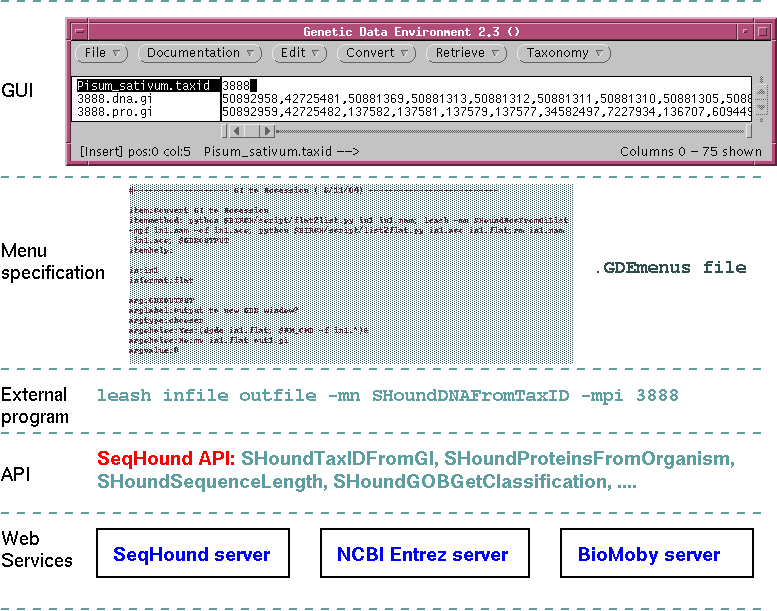
Data pipeline for generating statistics on databases
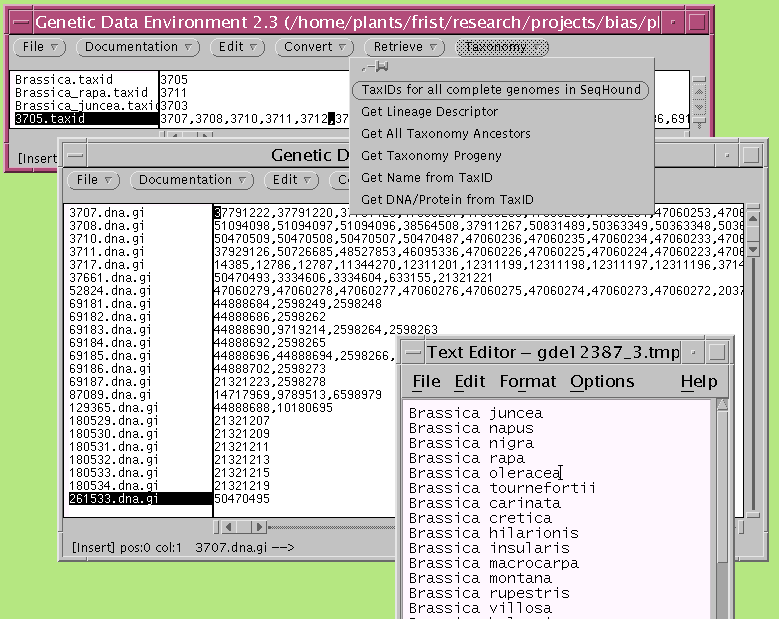
We use theGDEinterface by Steven Smith to call web services which provide the raw data.
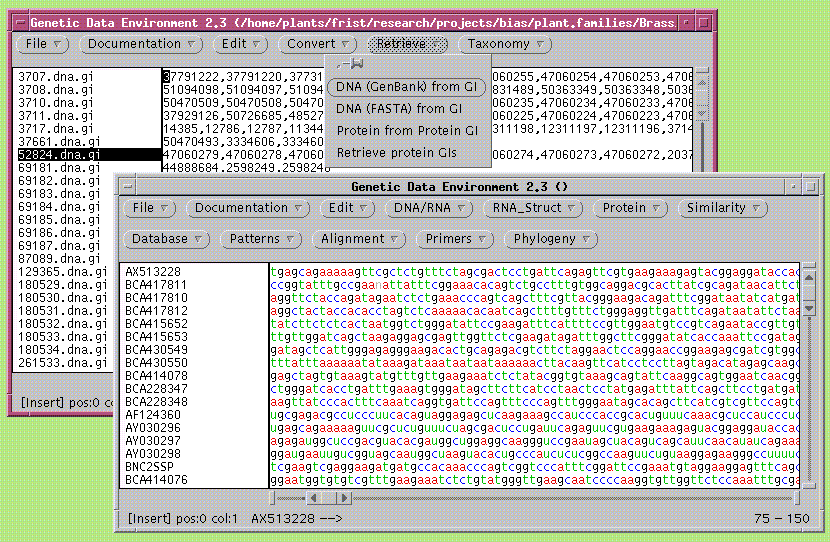
In turn, the actual GenBank entries corresponding to the list of GI numbers can be retrieved:
The new GDE window has menus for working with sequence data. In this
fashion, the same GDE interface can be used to go back and forth
between different types of data.
GDE is designed for rapid addition of new functions. GDE itself does nothing but display data and call external programs. Therefore, any existing program can be added to GDE's functionality, simply by adding a menu specification.