Rationale
Assumption underlying most types of analysis:
The dataset is representative of the natural population
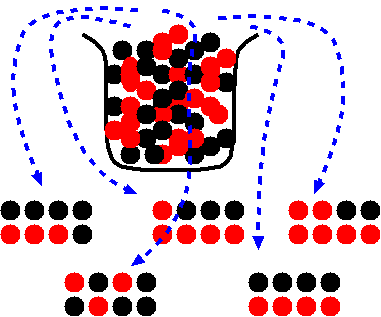
eg. Every time we pull marbles from a jar, we should get roughly the same number of red and black marbles.
We should be able to estimate the percentages of red and black marbles by counting any of the samples.
Problem: What if the marbles in a sample were NOT chosen at random?
How can we discover the types of biases that exist in biological databases, and how they influence our experiments?
http://home.cc.umanitoba.ca/~frist/Seminars/PlSci04/PlSci04.html