 |
Detecting
Biases in Genetic Databases, and Their Effects on Data Analysis
|
Dr. Brian Fristensky, Anil Amarakoon, Dept. of Plant Science
Zhingen Zhu, Dr. Dean Slonowsly, Dept. of Statistics
University of Manitoba
|
Detecting
Biases in Genetic Databases, and Their Effects on Data Analysis
|
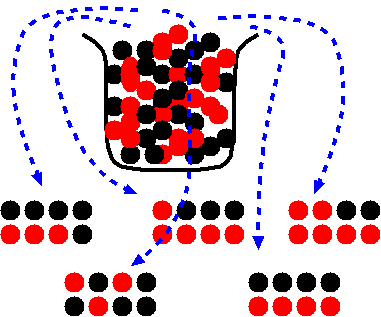
Assumption underlying most
types of analysis:The dataset is representative of the natural population |
 |
    |
 |