eg. Every time we pull marbles from a jar, we should get roughly the same number of red and black marbles.
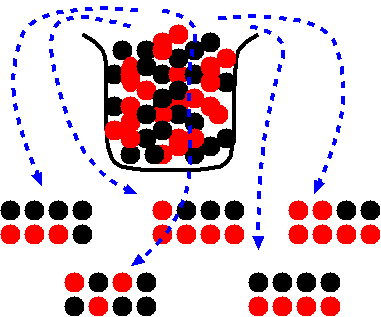
We should be able to estimate the percentages of red and black marbles by counting any of the samples.
Problem: What if the marbles in a sample were NOT chosen at random?

