Many models are useful for illustrating basic Mendelian genetics. Whether you use the fruit fly, corn, sweet pea or some other system the basic principles are applicable to all diploid systems including humans. We will be using corn to illustrate some of these principles. Mature corn plants produce ears that contain hundreds of seeds or kernels. Each seed is formed by the fertilization of an egg by a male gamete. Therefore, each kernel on an ear of corn can grow into a whole new plant. A complete ear represents a compact population of offspring which may be sampled.
The cob bears fruit (the seeds) which are either purple or yellow in color. The color of the corn fruit is inherited in exactly the same way as the color of the flowers on Mendel's peas. The cob above was taken from a corn plant which was a F2 plant resulting from an original parental cross between a homozygous purple fruit plant and a homozygous yellow fruit plant. The allele A (purple) is dominant over the recessive allele a (yellow).
Examine the cob above and answer the following questions:
- What proportion of the fruit on this cob do you expect from theory to be purple?
- What proportion do you expect to be yellow?

Click here for a diagramatic representation of a monohybrid cross using corn
Using more than 5 rows of fruits, count 100 fruits and record your results:
Purple
Yellow
Total 100
- Do these results agree with the proportions you expected?
Statistical Evaluation of the Results
If you flip an "honest" coin 10 times you may predict that you would get 5 heads and 5 tails, however in actuality you may obtain results which are quite different from the predicted, perhaps 6-4, 7-3, etc. Biologists frequently deal with observations (data) which deviate from the expected or predicted. The question then is whether or not the deviations observed between actual data and predictions are what you would expect by chance alone or whether other factors are involved. If the deviation from expected can not be explained by chance then perhaps the prediction is incorrect. Statistics allows the researcher, through mathematical examination of the data, to determine how closely the data fits predicted expectations, and whether or not deviation can be explained by chance.
Two important factors to consider in statistics are sample size and the way in which the sample is obtained. Obviously if you flip the coin just twice as compared to say 1000 times one might expect dramatically different proportions of heads and tails. If you made inferences about the entire population based on a sample of two you may come to some rather extreme conclusions. Not only must the sample be of sufficient size to accurately reflect the total population it must also be obtained in a random fashion.
We will be using the Chi-Square Test to see whether the data you have obtained from the monohybrid cross involving purple and yellow corn kernels fits your predicted values. The Chi-Square test is a statistical test frequently used to see whether data obtained in a genetic cross fits a predicted ratio. The formula for Chi-Square is:
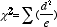
d = deviation from the expected
e = expected value
Use the data that you obtained by counting 100 kernels of corn to complete the following table:
Expected Purple
Kernals |
75
|
Deviation |
Deviation Squared |
Deviation Squared / Expected (75) |
Observed Purple
Kernals |
______
|
______
|
______
|
______
|
|
Expected Yellow Kernals |
25
|
Deviation |
Deviation Squared |
Deviation Squared / Expected (25) |
Observed Yellow Kernals |
______
|
______
|
______
|
______
|
Sum the final two cells to determine your chi-Square value.
- Was the sample a random sample?
- Can you think of a way to count to insure a random sample?
You can also use the following to calculate your value. However, you must understand how the calculation is made for examination purposes.
CHI-SQUARE CALCULATOR
Enter the observed number and the expected ratio below.
Observed # Ratio
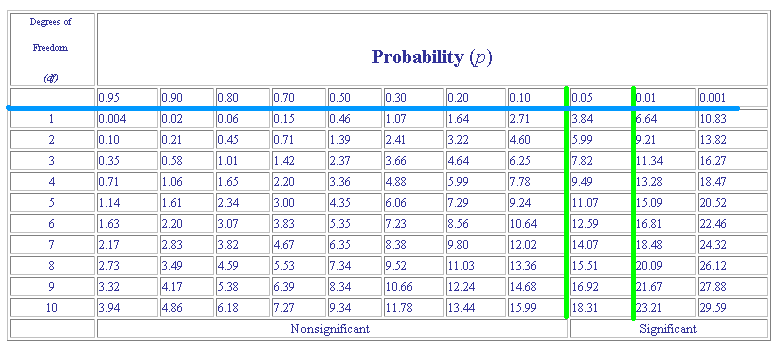
Interpretation of CHI-SQUARE
The
value is then used to determine how good a fit there is between the observed values and the expected values. If you have an exact fit (i.e. the observed is the same as the expected) the value of
- If you were using the results of the F2 of a dihybrid cross for calculating a
Evaluation of the Results:
Examine the table of
First published Sept 95: Modified June 2019
Copyright © Michael Shaw 2019 (Images and Text)
![]() Return
to Biology Home
Return
to Biology Home ![]() Back
to Lab Index
Back
to Lab Index ![]() Forward
to Next Page
Forward
to Next Page ![]() University
of Manitoba Home
University
of Manitoba Home