KEY CONCEPTS
This section introduces some concepts
that will help you leverage the power of Unix to work more
efficiently.
A video covering these topics can be viewed at:
 What most biologists probably
don't know about computers (57:39)
What most biologists probably
don't know about computers (57:39)
1. The Computer: What's under the hood,
and when does it matter
2. The Home Directory: Do
everything from the comfort of your $HOME
3. Organizing your files: A place
for everything, and everything in its place
4. Text files: It's actually quite
simple
5. Screen Real Estate: Why one
window should not own the screen.
6.
Network-centric
Computing - Any user can do anything from anywhere
1. The Computer: What's under the
hood, and when does it matter
1.1 What is
Unix/Linux?
Unix is an
operating system, that is, an environment, that provides commands
for creating, manipulating, and examining datafiles, and running
programs. But behind the scenes, an operating system also manages
system resources, and orchestrates the running of anywhere from
dozens to hundreds of programs that may be running at the same
time. Some other operating systems with which you may be familiar
are MS-Windows, Macintosh OSX. Despite their differences, all of
these operating systems do essentially the same things, which is
to act as the unifying framework within which all tasks are
performed.
Unix is
usually the system of choice for scientific and mathematical work,
as well as for enterprise-level systems and servers. This is
because Unix was designed as a multitasking, multiuser, networked
system with that had to be reliable and responsive under heavy
loads, have 24/7 availability, and be highly secure.
MS-Windows
was designed as a single-user desktop system, primarily for
running one program at a time. Higher-level capabilities such as
networking, multitasking, running several simultaneous users, and
server functions have all been retrofitted into Windows. Security
has long been, and is still a serious problem on the Windows
platform.
The Unix
family of operating systems include commercial Unix systems such
as Sun's Solaris, and the many different distributions of Linux,
most of which are free, as well as Apple's proprietary OSX.
 Linux
vs. Unix - Strictly speaking, Unix is a proprietary
operating system owned by ATT. Linux is a Unix-like operating,
written from scratch to function like Unix. Linux is Open Source
software. There are numerous Linux distributions, most of them
freely-avaliable, as well as value-added commercial distributions.
Many people use the terms Unix and Linux interchangeably.
Linux
vs. Unix - Strictly speaking, Unix is a proprietary
operating system owned by ATT. Linux is a Unix-like operating,
written from scratch to function like Unix. Linux is Open Source
software. There are numerous Linux distributions, most of them
freely-avaliable, as well as value-added commercial distributions.
Many people use the terms Unix and Linux interchangeably.
1.2
Beyond the standalone PC: The network is the computer
1.2.1 Every PC is a special case
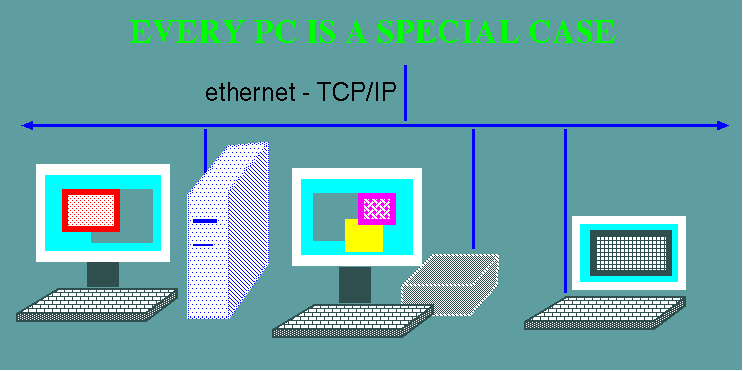
- Each computer
is a bit different from every other
- Everything
happens on your PC
- Your data
tends to be spread out among a number of machines
- Different
programs on different machines
- No way
to remotely login to most Windows PCs.
- How
many PCs actually get backed up?
1.2.2. The network is the computer
The
standalone PC is only one of many ways of using computer
resources. This figure illustrates the three main functions of
computers: File Services, Processing, and Display. The figure is
meant to be Generic. On A PC, all three functions occur in a
single machine. For this reason, a PC is sometimes referred to as
a "fat client".
However, there is no reason
that these functions have to be on the same machine. For
example, on distributed Unix systems, files reside on a
file server, processing is done on login hosts, and you
can run a desktop session on any login host, and the
desktop will display on a "thin
client". Because the thin client does nothing but
display the desktop, it doesn't matter what kind of
machine is doing the display. A thin client can be a
specialized machine or just a PC running thin client
software.
A compromise between a thin client is a fat client is the
"lean client".
Essentially, a lean client is a computer that carries out
both the Display and Processing functions, but remotely
mounts filesystems from the fileserver, which behave as if
they were on the machine's own hard drive. Many computer
labs are configured in this way to save on system
administration work, at the expense of extra network
traffic.
|
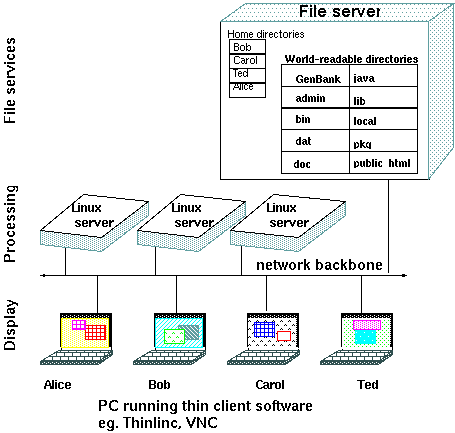 |
Advantages of network-centric computing:
- You can access your data from anywhere
- Full access to the resources of a datacenter from anywhere
- Protection from obsolescence, when you use thin clients
- High availability, because all components are redundant
- There is nothing to lose (eg. memory stick), nothing that
can be stolen (eg. laptop)
- Once software is installed, it works for everyone
- Automated backups
One example
of network-centric computing is Google
Docs.
Google Docs lets you maintain documents, spreadsheets,
presentations online, using any web browser. Your documents stay
on the server, so you can work on them from any browser on any
computer anywhere.
More and
more resources reside on the network. This is now referred to as "cloud computing":
- Databases - Remote
databases return data in response to queries from local
clients.
- Applications servers -
application runs on remote host, but displays on local client
- Web services - local
client sends data to web service; service returns the result
of the computation.
- Computing Grid - Analogous
to an electrical grid. A community of servers on a high-speed
backbone share computing resources, including CPU time.
Different parts of a job may be done on different machines,
transparently to the client.
|
All of network-centric
computing can be summarized in a single sentence:
Any user can do
any task from anywhere
|
1.3
File systems - share or serve?
Unix systems typically include many machines, all of which
remotely mount files from a file server. From the user's point of
view, it looks as if the files are on their own hard drive. There
are many advantages to using a file server. First, all machines on
a LAN will have the same files and directories available,
regardless of which desktop machine you use. Secondly, a file
server makes it possible to standardize best practices which
contribute to data integrity, including security protocols and
scheduled automated backups. Finally, file servers typically store
data redundantly using RAID protocols, protecting against of loss
of data due to disk failure.
Many LANs support peer to peer file sharing. In file sharing, each
PC on the LAN may have some files or directories that are
permitted to be shared with others. Again, from each user's
perspective, it looks as if the file is on their own hard drive.
However, file sharing also invites many potential security
problems. As well, data integrity is only as good as the hard
drive a file is actually on, and whatever steps the owner of that
PC may or may not have taken to back up files.
more: http://en.wikipedia.org/wiki/Shared_disk_access
1.4 The
Unix command line - Sometimes, typing is WAY easier than point
and click.
One of the
strengths of Unix is the wealth of commands available. While
typing commands might seem like a stone-age way to use a computer,
commands are essential for automating tasks, as well as for
working with large sets of files, or extracting data from files.
For example, when you use a DNA sequence to search the GenBank
database for similar sequences, the best matching sequences are
summarized, as excerpted below:
gb|EU920048.1| Vicia faba clone 042 D02 defensin-like protein mR... 143 1e-32
gb|EU920047.1| Vicia faba clone 039 F05 defensin-like protein mR... 143 2e-32
gb|EU920044.1| Vicia faba clone 004 C04 defensin-like protein mR... 143 2e-32
gb|FJ174689.1| Pisum sativum pathogenesis-related protein mRNA, ... 139 3e-31
gb|L01579.1|PEADRR230B Pisum sativum disease resistance response... 132 4e-29
There are
often dozens of hits. If you wanted to retrieve all matching
sequences from NCBI, you would need the accession numbers, found
between the pipe characters "|". Rather than having to copy and
paste each accession number to create a list for retrieval, a file
containing that list could be created in a single Unix command:
grep 'gb|' AY313169.blast | cut -f2 -d '|' > AY313169.acc
would cut out the accession
numbers from AY313168.blast and write them to a file
called AY313169.acc:
EU920048.1
EU920047.1
EU920044.1
FJ174689.1
L01579.1
This list could now be used to retrieve all sequences in
one step. |
Explanation: The grep command searches
for the string 'gb|' in the file AY313169.blast, and writes
all lines matching that string to the output. The next pipe
character sends that output to the cut command. The cut
command splits each line into several fields, using '|' as a
delimiter between fields. Field 2 from each line is written
to a file called AY313169.acc.
|
If you learn the commands listed below, you will be able to do the vast
majority of what you need to do on the computer, without having to learn
the literally thousands of other commands that are present on the system.
| cat |
Write and
concatenate files |
| cd |
Move to
new working directory |
| chmod |
Change
read,write, execute permissions for files |
| cp |
Copy
files |
cut
|
cut out one or more columns of
text from a file
|
grep
|
Search a file for a string
|
| less |
View
files a page at a time |
| logout |
Terminate
Unix session |
| lpr |
Send
files to lineprinter |
| ls |
List
files and directories |
| man |
Read or
find Unix manual pages |
| mkdir |
Make a
new directory |
| mv |
Move
files |
| passwd |
Change
password |
| rm |
Remove
files |
| rmdir |
Remove a
directory |
| ps |
list
processes |
| top |
list most
CPU-intensive processes |
| kill |
kill a
process |
more: UsingUnix
1.5 What do
programs actually do?
The cell is a good analogy
for how a computer works. An enzyme takes a substrate and
modifies it to produce a product. In turn, any product
might be used as a substrate by another enzyme, to produce
yet another product. From these simple principles,
elaborate biochemical pathways can be described.
Similarly, computer programs take input and produce
output. For example, program 1 might read a genomic DNA
sequence and write the mRNA sequence to the ouptut.
Program 2 might translate the RNA to protein, and Program
3 might predict secondary structural characteristics for
the protein. Alternatively, program 4 might predict
secondary structures from the mRNA.
The process of chaining together several programs to
perform a complex task is known as 'data pipelining'.
|
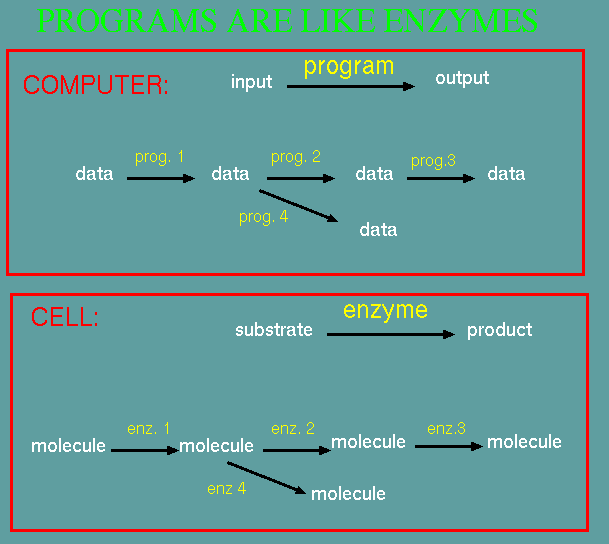 |
One subtlety that is
sometimes missed about computers has to do with the roles
of random access memory (RAM) and the hard drive. Programs
don't actually work directly on files that are on the hard
drive. When you open a file in a
program, a copy of that file is read from disk and written
into memory. All changes that you make to the file occur
on the copy in memory. The original copy of the
file on disk is not changed until you save the file.
At that time, the modified copy in memory is copied back
to disk, overwriting the original copy.
|
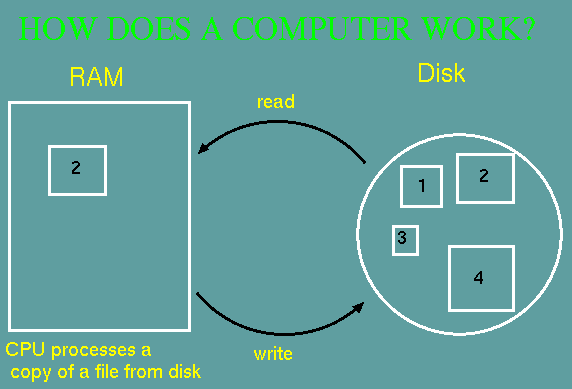 |
2. The Home Directory*: Do everything from the comfort
of your $HOME
One of the features of Unix that makes contributes to its
reliability and security, and to its ease of system
administration, is the compartmentalization user and system data.
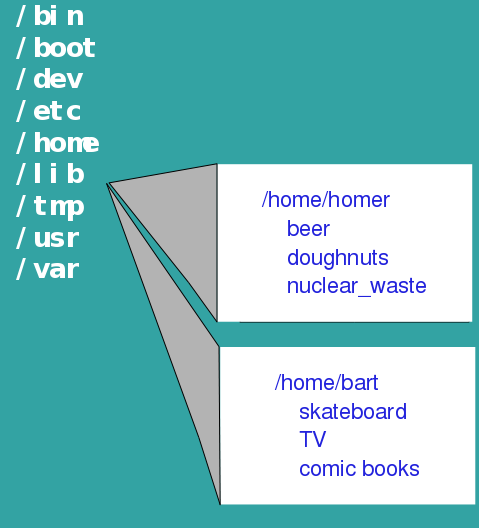
The figure below shows the highest-level directories of the
directory tree. To cite a few examples, /bin contains binary
executables, /etc contains system configuration files, and /usr
contains most of the installed applications programs.
One of the most important directories is /home, the directory in
which each user has their own home directory. Rather than having
data for each user scattered across the directory tree, all files
belonging to each user are found in their home directory. For
example, all files belonging to a user named 'homer' has a are
found in /home/homer. Subdirectories such as 'beer', 'doughnuts',
and 'nuclear_waste' organize his files into topics. Similarly the
home directory for 'bart' is /home/bart, and is organized
according to bart's interests.
Most importantly, the only place that homer or bart can create,
modify or delete files is in their home directories. They can
neither read nor write files anywhere else on the system, unless
permissions are specifically set to allow them to do this. Thus,
the worst any user can do is to damage their own files, and the
files for each user are protected.
* In Unix, the term directory is synonymous with folder.
The two can be used interchangeably.
 |
- usually
work
in home directory
- all
your
data is in your home dir. and nowhere else!
- system
directories
are world-readable
- each
user
can only read/write their own home directories
|
3. Organizing your files: A place for
everything, and everything in its place
Most people
know about organizing their files into a tree-structured hierarchy
of folders. On Unix you can organize your files using a file
manager such as Nautilus.
Some good guidelines to follow:
- Organize your files by topic, not by type. It makes no
sense to put all presentations in one folder, all images in
another folder, and all documents in another folder. Any given
task or project will generate files of many kinds, so it makes
sense to put all files related to a particular task into a
single folder or folder tree.
- Each time you start a new task or project or experiment,
create a new folder.
- Your home directory should be mostly composed of
subdirectories. Leave individual files there only on a
temporary basis.
- Directory organization is for your convenience. Whenever
a set of files all relate to the same thing, dedicate a
directory to them.
- If a directory gets too big (eg. more files than will fit
on the screen when you type 'ls -l'), it's time to split it
into two or more subdirectories.
- On Unix/Linux, a new account will often have a Documents
directory, which is confusing and makes no sense, since your
HOME directory already serves the purpose of a Documents
directory in Windows. It is best to just delete the Documents
directory and work directly from your HOME directory.
4. Text files: It's actually quite simple
A text editor is a program
that lets you enter data into files, and modify it, with a
minimal amount of fuss. Text editors are distinct from
word processors in two crucial ways. First, the text
editor is a much simpler program, providing none of the
formatting features (eg. footnotes, special fonts, tables,
graphics, pagination) that word processors provide. This
means that the text editor is simpler to learn, and what
it can do is adequate for the task of entering a sequence,
changing a few lines of text, or writing a quick note to
send by electronic mail. For these simple tasks, it is
easier and faster to use a text editor.
Two of the most commonly used text editors with graphic
interfaces are Nedit
and gedit.
Both are available on most Unix and Linux systems.
|
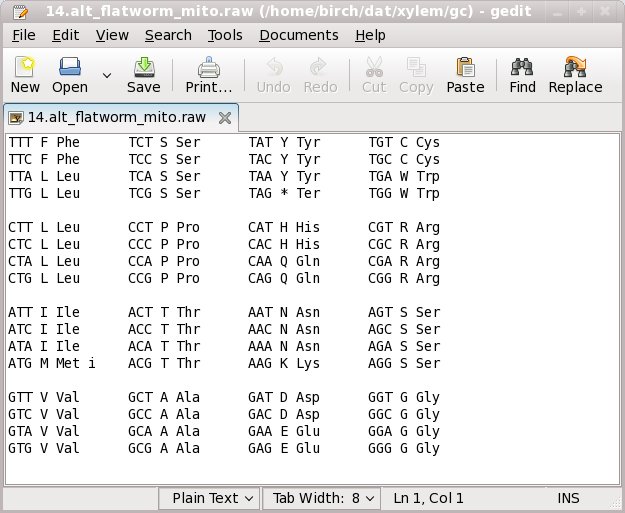
Example of a text editor editing a computer-readable file
specifying an alternative genetic code used in flatworm
mitochondria.
|
The second
important difference between word processors and text editors is
the way in which the data is stored. The price you pay for having
underlining, bold face, multiple columns, and other features in
word processors is the embedding of special computer codes within
your file. If you used a word processor to enter data, your
datafile would thus also contain these same codes. Consequently,
only the word processor can directly manipulate the data in that
file.
Text editors
offer a way out of this dilemma, because files produced by a text
editor contain only the characters that appear on the screen, and
nothing more. These files are sometimes referred to as ASCII
files, since they only contain standard ASCII characters.
Generally,
files created by Unix or by other programs are ASCII files. This
seemingly innocuous fact is of great importance, because it
implies a certain universality of files. Thus, regardless of
which program or Unix command was used to create a file, it can
be viewed on the screen ('cat filename'), sent to the
printer ('lpr
filename'), appended to another file ('cat filename1 >>
filename2'), or used as input by other
programs. More importantly, all ASCII files can be edited with
any text editor.
If you plan to
do a lot of work at the command line, you will need a text editor
that does not require a graphic interface. Several common editors
include:
- nano - A very simple but
not very powerful editor
- vi
- The vi editor is the universal screen editor available with
all UNIX implementations.
- emacs - a
text editor with many advanced capabilities for programming;
it also has a long learning curve
5. Screen Real Estate: Why one window should
not own the screen.
The so-called "desktop metaphor" of today's workstations is
instead an "airplane-seat" metaphor. Anyone who has shuffled a
lap full of papers while seated between two portly passengers
will recognize the difference -- one can see only a very few
things at once. - Fred Brooks, Jr.
One of the most counter-productive legacies from the early
PC era is that "One window owns the screen". Many
applications start up taking the entire screen. This made
sense when PC monitors were small with 800x600 pixel resolution.
It makes no sense today when the trend is toward bigger monitors
with high resolution. The image below shows a typical Unix screen,
in which each window takes just the space it needs, and on more.
Particularly in bioinformatics, you will be working on a number of
different datafiles, or using several different programs at the
same time. The idea is that by keeping your windows small, you can
easily move from one task to another by moving to a different
window.
Most Unix
desktops today give you a second way to add more real estate to
your screen. The toolbar at the lower right hand corner of the
figure shows the Workplace Switcher. If the current screen gets
too cluttered with windows, the workspace switcher lets you move
back and forth between several virtual screens at the click of a
button. This is a great organizational tool when you have a number
of independent jobs going on at the same time.
6.
Network-centric Computing - Any user can do anything from
anywhere
6.1. Running
remote Unix sessions at home or when traveling
Since all Unix and Linux systems are servers, you can always run a
Unix session from any computer, anywhere.
see Using Unix from
Anywhere
6.2. Uploading and downloading files across the network
Email is
usually not the best way to move files across a network.There are
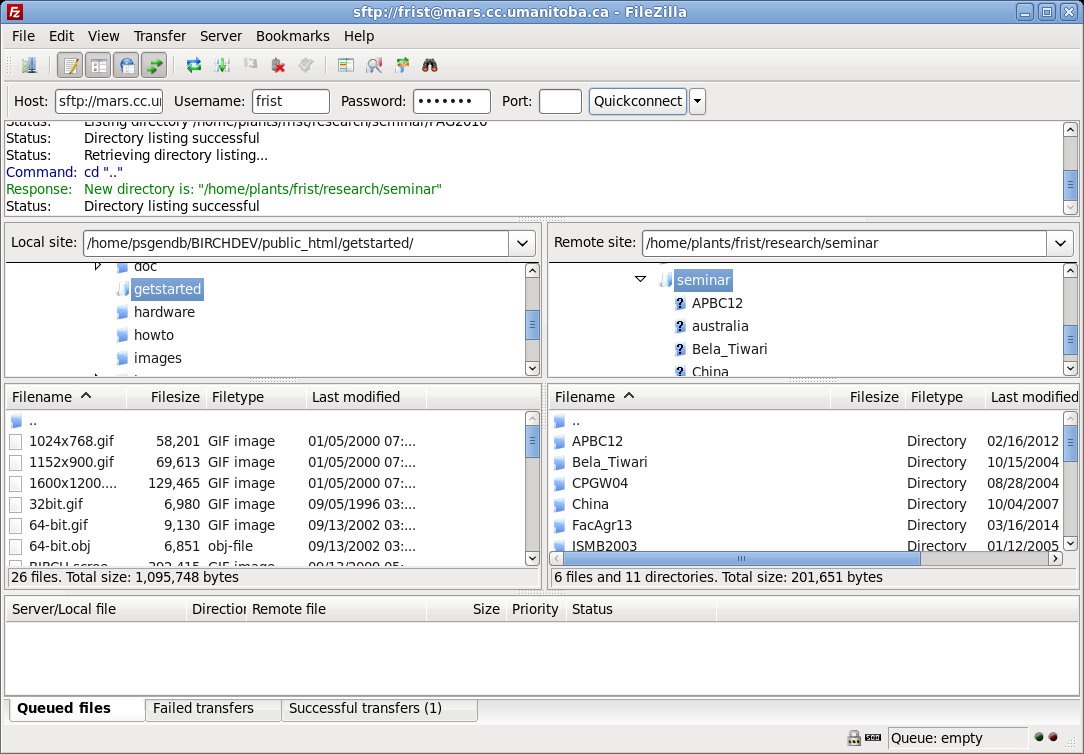
better tools for this purpose. On Unix and Linux systems, one of
the best tools is Filezilla. Filezilla gives you two panels, one
for viewing files on the local system, and the other for viewing
files on the remote system. In the example below, the left panel
shows folders in the user's local home directory. The right panel
shows the user's files on the server. Copying files, or entire
directory trees from one system to the next is as easy as
selecting them in one panel and clicking on the appropriate green
arrow button. For security, Filezilla uses ssh to encrypt all
network traffic, so that no one can eavesdrop on your upload or
download. Filezilla is freely available for download at https://filezilla-project.org.
In
the example at right, the user logs into the remote server
by filling in the boxes as shown:
Host - name of remote
server (eg. at Univ. of Manitoba, these are
mars.cc.umanitoba.ca, venus.cc.umanitoba.ca,
jupiter.cc.umanitoba.ca)
Username - your Unix userid
Password - password
Port: can probably be blank, but if necessary type
'22' to indicate a secure connection on port 22 using ssh.
Click on Quickconnect to login.
|
 |
