An AQL query is sumbitted as plain text that contains keywords, database indentifiers (e.g. names of tags and classes) and language specific tokens (e.g. ->, ::, []) which are translated into an internal representation of the query for further processing.
The lex/yacc system
is used to generate program fragments that build the AQL parser.
This strategy allowed us to build a comprehensive parser in a well
structured and almost self-documenting manner, as the source-files
for lex/yacc closely relate the documentation of the
AQL syntax).
The drawback is the inablity of a lex/yacc generated parser to
present meaningful error-messages to the user in the event of
a syntax error. However, errors messages reported during the
preprocessing stage are much more
explanatory.
The source file for lex is aqlparse.l. It defines all language keywords, operators and lexical rules for identifiers, numeral constants and date values.
The interface to the lex/yacc system isn't threadsafe and the C-module which is comprised of lex and yacc-generated code has a global static variable aql_L which holds all global status of the query that the various code-snippets access.
The API to lex/yacc is quite restrictive and its POSIX standard requires that the input has to be a FILE* pointer. Various loopholes in the API allowed us to read the lex input directly from a text-buffer containing the query-string. Note that those loopholes are different in AT∓T based lex implemetations and the GNU lex-clone flex. See the comments at the top of aqlparse.l for details.
Furthermore, the limited API only allows the programmer to keep track of the line-number of each token. This is very restrictive for AQL queries which in most cases constist only of one line of text. For better error-reporting the array tokPos[] is used to keep track of the position of a token in the query-string. Errors reported in the preprocessing stage can therefore point to the specific word in the querystring that was responsible for the error. (see aqlerror.c:aqlError())
The source file for yacc is aqlparse.y. It defines the language syntax in BNF grammar and contains the code sippets that build the parse-tree.
The parse-tree is made up from nodes of various types wich are enumerated by the enum-type AqlNodeType in in the header-file aql_.h. The is no direct relationship between the enum-identifiers used in aqlparse.l and the node-types. The token-identifiers used by the lexer generally correspond directly to the keyword that they represent, whereas the identifiers of the node-types decribe the language construct.
The utility taql is a test-bed for aql queries and provides a few hooks into the AQL internals than tace which allows nothing but the input of a query-text. The most useful function is the ability to turn on the debugging flags in the AQL kernel.
% taql -d 2 $ACEDB
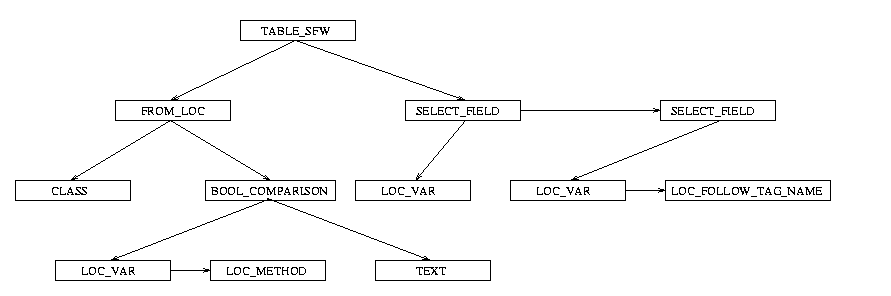
The debug level 2 will output a textual parse-tree, which is useful to study how the query is processed at each stage. Let's study an example of a parse-tree at the parsing stage, i.e. the tree directly constructed by aqlparse.y
This example query will be converted into the following parse-tree :
select a, a->paper from a in class author where a.name like "m*"
TABLE_SFW 1405c0460 left FROM_LOC name "a" 1404da3a0 left CLASS name "author" 1404da440 right BOOL_COMPARISON op like 1405c03c0 left LOC_VAR name "a" 1404da4e0 next LOC_METHOD name "name" 1404da580 right TEXT m* 1405c0320 right SELECT_FIELD 1404da120 left LOC_VAR name "a" 1404c7380 next SELECT_FIELD 1404da300 left LOC_VAR name "a" 1404da1c0 next LOC_FOLLOW_TAG_NAME name "paper" 1404da260
The nodes in the tree are linked by pointers left, right and next and the tree is traversed recursivly in that order. The memory addresses in italics may be ignored for now, they can be used when nodes-structures are inspected in the debugger. The words in bold are the names of each node as declared by the AqlNodeType enumerator in aql_.h
The graphical representation of the debug-output would look like this :
|
The graphical tree has 4 levels, that correspond to the 4 indentation levels
of the debug output. The types of nodes that are allowed for the
left, right and next pointers varies for each type
and implies a different meaning depending on each type of node.
At this stage the parse tree is still very unorganised and needs to be pre-processed before it can be executed to produce the query-results. Part 2 : PreprocessingThe parse-tree is quite dramatically altered at this stage. The goal is to turn the parsetree into a canonical form which can be executed and is guaranteed to be syntactically and semantically correct. The pre-processing is divided into 2 main parts, which are performed by the functions aqlcheck.c:aqlCheck1() and aqlrun.c:aqlCheck2(). During check1 the parse-tree is converted into a canonical form ready for query execution and check2 accesses the database to verify the validity of identifiers such as class-names and tag-names. An important concept to the internals of the AQL engine is the locator.
A locator is a data-carrier for certain nodes, which provides valuable
linkage information across the tree. In the debug-ouput below, one can see,
that the LOC_VAR "a" is mentioned multiple times in the
tree, but careful examination of the locator address reveals that all these
node carry the same locator (loc=1405d2e20). Therefore the state
of the variable "a" will be the same whichever part of the parse is looking
at it, e.g. a.name and a->paper will eventually
only have to eveluate "a" once, and then the result of the name-method
and the dereferncing to the tag "paper" will be based on the same value for "a". Check1> :The debug output of the canonical parse-tree after semantic pre-processing : TABLE_SFW 1405c0460 left FROM_LOC name "a" 1404da3a0 (loc=1405d2e20) left CLASS name "author" 1404da440 next FROM_LOC name "_1" 1405d1660 (loc=1405d2ec0) left LOC_VAR name "a" 1405d1700 (loc=1405d2e20) next LOC_METHOD name "name" 1404da580 next FROM_LOC name "_2" 1405d17a0 (loc=1405d2f60) left LOC_VAR name "a" 1405d1840 (loc=1405d2e20) next LOC_FOLLOW_TAG_NAME name "paper" 1404da260 next FROM_LOC name "_3" 1405d18e0 (loc=1405d30a0) left LOC_VAR name "_2" 1405d1980 (loc=1405d2f60) next LOC_LOCAL_POS number 1 1405d1520 right BOOL_COMPARISON op like 1405c03c0 left LOC_VAR name "_1" 1404da4e0 (loc=1405d2ec0) right TEXT m* 1405c0320 right LOC_VAR name "a" 1404c7380 (loc=1405d2e20) next LOC_VAR name "_3" 1404da1c0 (loc=1405d30a0) The graphical representation of the debug-output would look like this : |
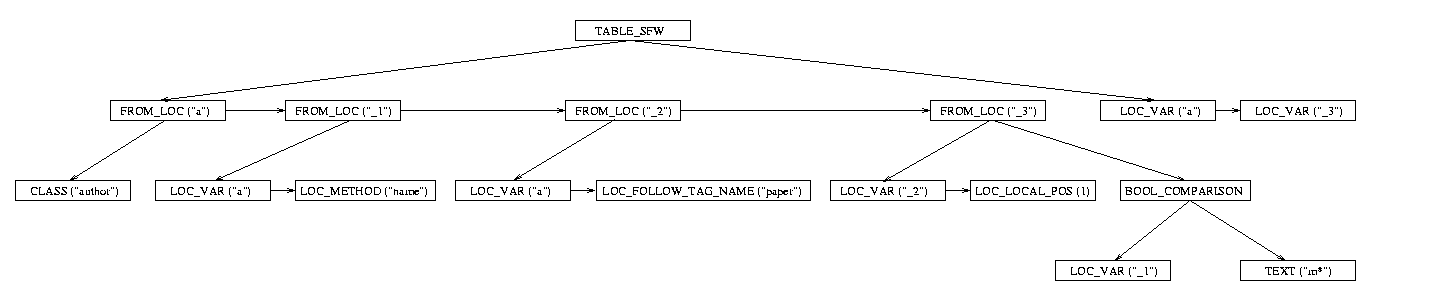
|
The parse-tree has gained a lot of new nodes and some nodes have even been lost.
The guts of the query have been converted to a series of FROM_LOC
nodes which are reminiscent of the from keyword. They are the declarations
of internal iterators. The user has already declared one iterator ("a")
in the from-clause of the query. This iterator is class-based and will
therefore loop over all objects in the class "Author". The other iterators (with names like "_1") have been added by the check1 pre-processor. The reader is reminded of the convention on positions in an Acedb-model. From every tag you can move a certain number of steps to the right to retrieve a specific data-field. In AQL the default tag-position is 1, i.e. the expression a->paper really means a->paper[1] and will therefore return the data-element which is one position to the right of the tag "paper" in an Author-object. The tag-position 0 refers to the tag itself. The pre-processor will create some extra tag-positiong nodes where the user has not specified one. The SELECT_FIELD nodes have disappeared, after some processing they are no longer required, because the node to the right of a TABLE_SFW node automatically identifies itself as a select-field. The 2 select-fields are preserved as LOC_VAR nodes. This query will report 2 columns with the values of the locators "a" and "_3" at each iteration cycle. Where did the "_3" variable come from ? The variable with names that start with an underscore "_" are internal variables. They could have been declared by the user, but usually the query is presented in a somewhat abbreviated form. Internally, the query generates 4 results :
So, all the internal iterators become a linked list of FROM_LOC
nodes attached to the left of the TABLE_SFW node, which is
the root-node. If a variable is declared to be based on a table-variable
(e.g. The where-clause was parsed straight into the appropriate BOOL_...
node by the yacc-parser without the need of intermediate WHERE_...
nodes (like those needed for the The operands of the where-clause expression can only refer to previously declared LOC_VARs. That's why the previous declaration of FROM_LOC "_1" is required. The BOOL_COMPARISON node is fairly straight forward - it's operator is the like function which compares the left node's value to the right node's value. If TRUE, the locator "_3" is valid and the LOC_VAR node "_3" in the select-clause will therefor report the result. The parse-tree now represents the query in a canonical form which contains all the internal declarations needed for the query execution. Check2 : The parse-trees is checked against the database. It also determines how the internals locators will be executed. This is the debug output of the parse-tree after aqlCheck2() : TABLE_SFW 1405c0460 left FROM_LOC name "a" 1404da3a0 (loc=1405d2e20, IS_CLASS) left CLASS name "author" 1404da440 next FROM_LOC name "_1" 1405d1660 (loc=1405d2ec0, IS_METHOD) left LOC_VAR name "a" 1405d1700 (loc=1405d2e20, IS_CLASS) next LOC_METHOD name "name" 1404da580 next FROM_LOC name "_2" 1405d17a0 (loc=1405d2f60, IS_FOLLOW_TAG) left LOC_VAR name "a" 1405d1840 (loc=1405d2e20, IS_CLASS) next LOC_FOLLOW_TAG name "paper" 1404da260 next FROM_LOC name "_3" 1405d18e0 (loc=1405d30a0, IS_LOCAL_POS) left LOC_VAR name "_2" 1405d1980 (loc=1405d2f60, IS_FOLLOW_TAG) next LOC_LOCAL_POS number 1 1405d1520 right BOOL_COMPARISON op like 1405c03c0 left LOC_VAR name "_1" 1404da4e0 (loc=1405d2ec0, IS_METHOD) right TEXT m* 1405c0320 right LOC_VAR name "a" 1404c7380 (loc=1405d2e20, IS_CLASS) next LOC_VAR name "_3" 1404da1c0 (loc=1405d30a0, IS_LOCAL_POS) The parse-tree has largely unchanged, but the locators have been assigned types. Those types will dictate how a node is treated during query execution. Part 3 : Query executionThe parse-tree can now be passed to the function aqlrun.c:aqlEval() which executes the query starting from the root. Fuzzy logic : The query is executed twice, in fuzzy and non-fuzzy mode.
The first-pass in fuzzy mode will never open any objects and therefore
execute very quickly. Any result in fuzzy mode can have one of 3 states :
NULL, FUZZY or KNOWN. Some queries can be satisfied
without ever having to open any objects and will return a KNOWN-value
after the fuzzy-pass (which saves time). The execution loop : The guts of the query-execution is the linked list of
FROM_LOC nodes which is attached to the left of
the TABLE_SFW node.
The type of each locator specifies the way it is being processed. There are single-valued and multi-valued locators. In our example there are the following types :
The other important part of the query-execution loop is the processing of
each locator at every stage in the loop. Every locator is subjected to this
(aqlrun.c:processThisLoc()) at the end of a loop-cycle.
To find out whether the locator is valid we need to check for its where-clause
and evaluate it if necessary. The boolean value of the expression-node
which is attached to the right of a FROM_LOC node is used
for this decision. If the where-clause expression is TRUE we can move
on to the next FROM_LOC node to advance the cycle.
The loop can now continue and the recursion will bubble up to the last multi-valued node that wasn't yet exhausted. Thereby every possible combination is visited and the results are gathered row-by-row in the results-table which is attached to the top-level TABLE_SFW node. When the recursion has finished this table-value is returned as the final result. written by Fred Wobus, 06/Dec/1999 acedb@sanger.ac.uk |