| |
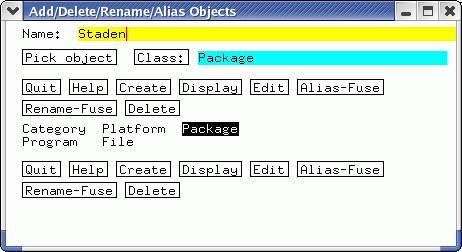
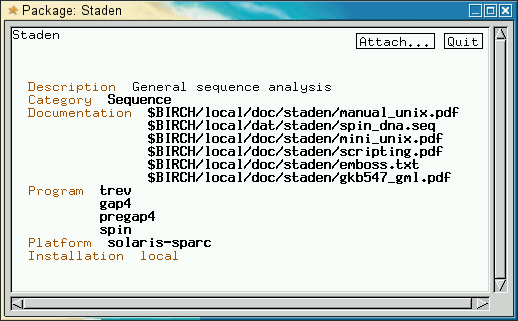
BIRCH - Adding documentation for locally-installed programs |
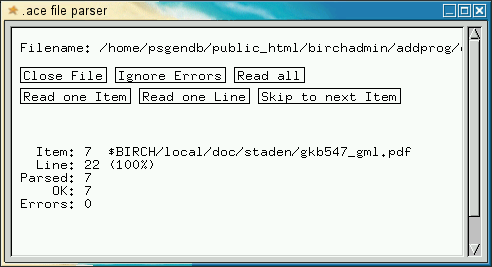
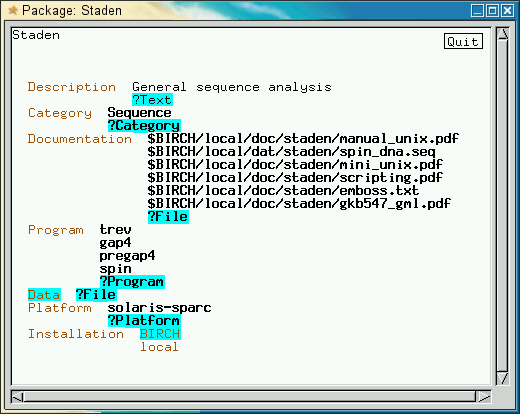
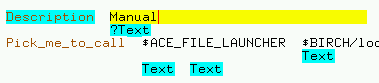 Type in a short
title that describes this file and press the
ENTER key. (You can get out of a yellow field by right-clicking and
choosing 'Cancel'. Usually, the shorter the title, the better. Right
click again and choose 'Save'. Your window should look like this:
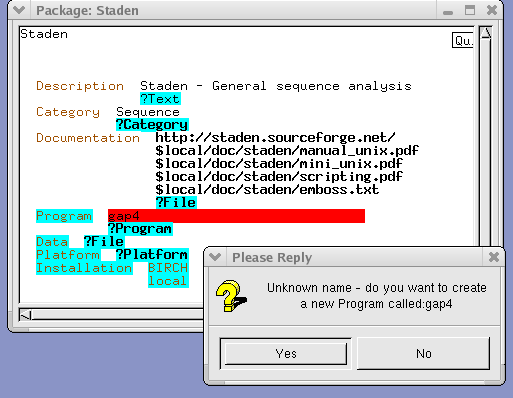
Type in a short
title that describes this file and press the
ENTER key. (You can get out of a yellow field by right-clicking and
choosing 'Cancel'. Usually, the shorter the title, the better. Right
click again and choose 'Save'. Your window should look like this: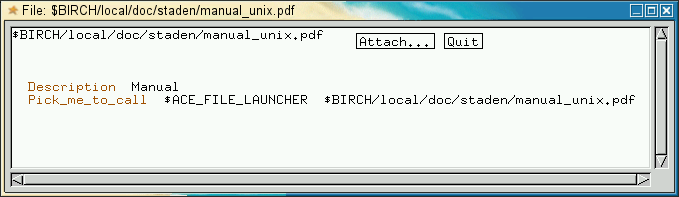
| What's going on
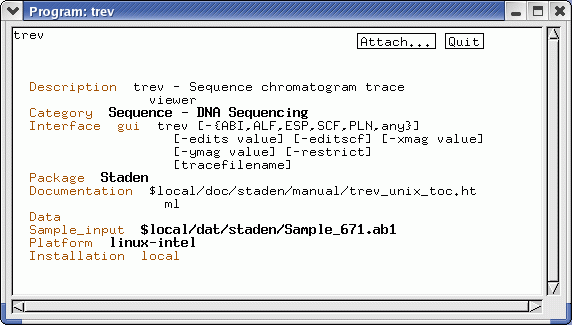
here? The environment variable $ACE_FILE_LAUNCHER specifies a script used to launch a file. Pick_me_to_call generates a Unix command consisting of the name of the script, followed by the filename. Since the lbircdb script sets $ACE_FILE_LAUNCHER to 'chooseviewer', the actual command that is run is chooseviewer $BIRCH/local/doc/staden/manual_unix.pdf The chooseviewer script works a lot like MIME, in that it chooses the viewer based on the file extension. For each file extension (eg. pdf, ps, html, jpg) a script is called that knows how to handle each kind of file. |