Nonetheless, it should be
possible to use 'defensin' as a starting point, and build a dataset
in several steps.
| Note: The sequence dataset constructed in this exercise should be considered a 'first draft'. For example, many of the proteins listed in these GenBank entries are referred to in the annotation as 'defensin-like proteins'. Several rounds of multiple sequence alignment and phylogenetic analysis may be required before a decision can be reached as to which proteins to consider an orthologous group, and which to exclude from the group. |
mkdir defensin
cd defensin
| Writing
a Query Statement Entrez lets you do highly specific searches by creating search statements in the following form: term
[field] OPERATOR term [field]
where term is a search string, limited to a specific field. The field must be enclosed in sequare brackets. One or more term-field statements can be joined using the operators AND, OR or NOT, which must be capitalized. See Writing Advanced Search Statements in the Entrez Help book for complete information. For the Nucleotide database, a list of fields can be found in Table 3. |

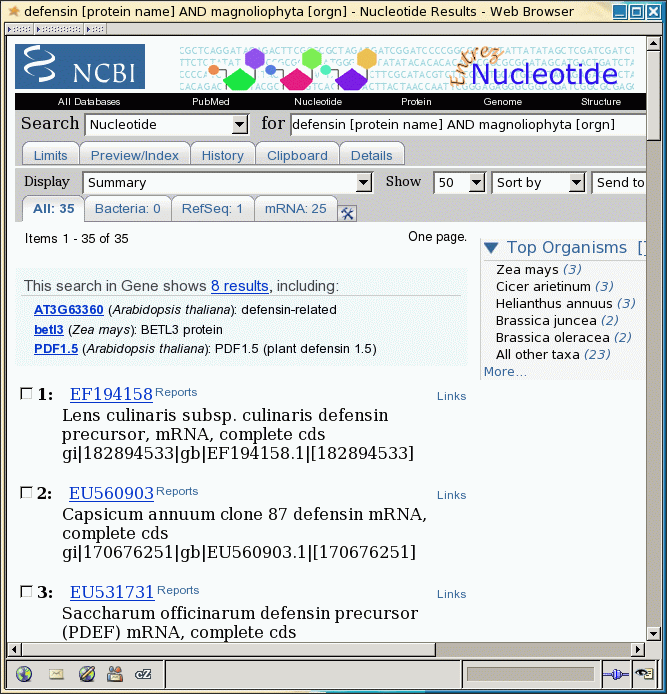
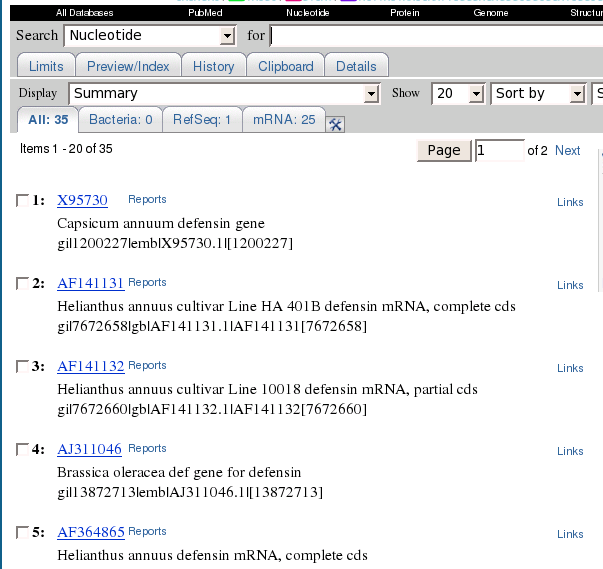
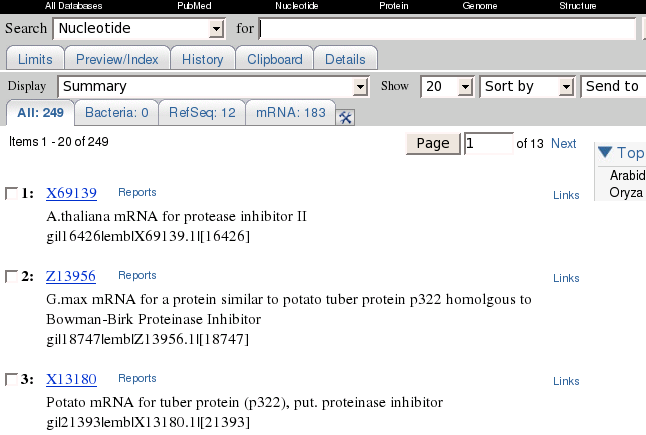
In this example, 35 hits
were found.
At this point, the most
direct way to save the sequences is to change the Display to 'GenBank Full' and Send To
to 'Text'. This would display a plain text representation of the 35
GenBank entries, which could then be saved to a file using the Save As
function in your browser. The problem with this approach is that when
the hits include very long sequences or a large number of sequences,
retrieval of the entire set of sequences to the browser is sometimes
not reliable.
A more reliable way is to
save the GI numbers for all hits to a file, and use the GI numbers to
retrieve the actual sequences.
Set Display to 'GI List'. For convenience, change Show to 50 so that all hits appear in a single window.
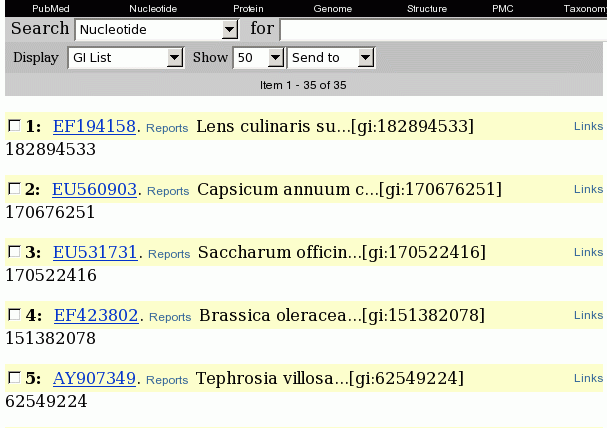
Next, change Send To to
'File'. You will be prompted for the name of a file. Save the file in
the defensin directory
under the name temp.gi.
To retrieve the GenBank entries, we'll use Batch Entrez at http://www.ncbi.nlm.nih.gov/entrez/batchentrez.cgi?db=Nucleotide.


Next, choose Database
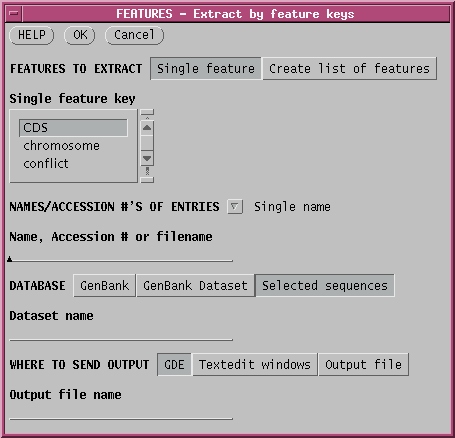
--> FEATURES - extract by feature keys.
|
Set the 'Single feature key' menu to 'CDS'. Under DATABASE, click on 'Selected sequences' to tell FEATURES to extract subsequences from the sequences you have selected. (By default, FEATURES would first retrieve sequences from GenBank, which has already been done, in this case.) The menu should look like this: |
|
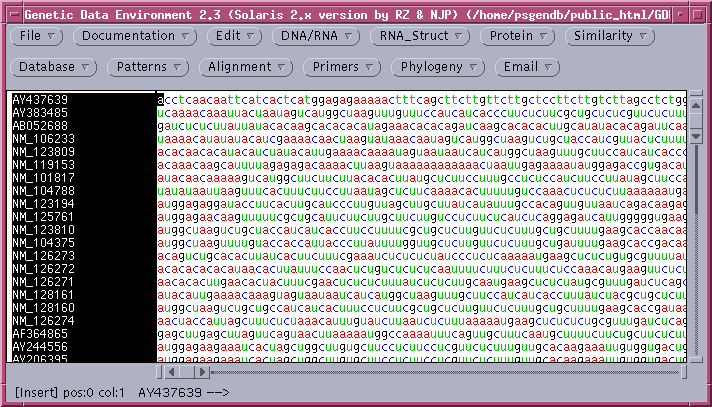
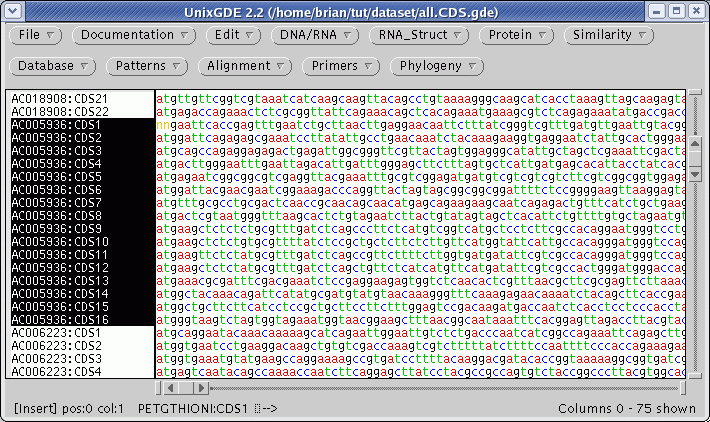
The protein coding regions (CDS) will be extracted into a new GDE window:
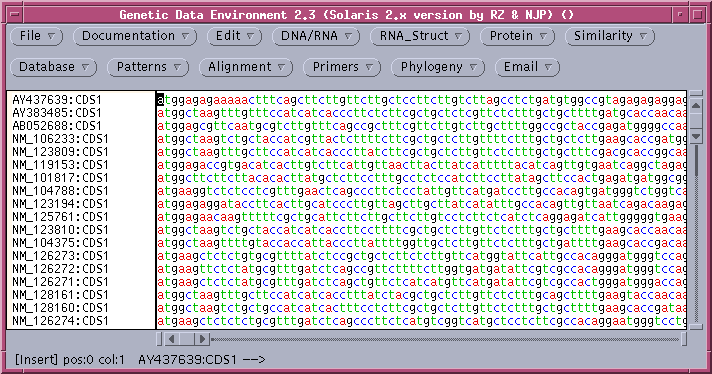
Consistent with the fact that protein coding regions have been extracted from the total DNA sequences, all of the CDS regions begin with 'atg'. These can be translated in one step by selecting all sequences and choosing DNA/RNA --> Ribosome. By default, ribosome sends output to a new GDE window.
![]()
| To
find other proteins related to defensins, we can run BLAST searches of
defensin proteins versus translated GenBank sequences. Our first choice
of a test sequence will be
AY313169, a defensin homologues from the barrel medic (Medicago
truncatula). |
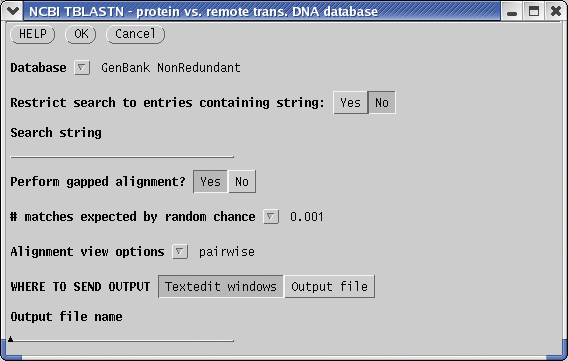 |
Be patient! The BLAST search may take several minutes, depending on the load on the server.
Output will appear in two popup textedit windows. Save the BLAST report using the file name AY31369.tblastn, and the accession numbers of the hits in AY31369.tblastn.acc.
Output:
AY313169.tblastn - program outputAnother search was done with using a defensin from bell pepper (Capsicum annum):
AY313169.tblastn.acc - accession numbers of hits
Output:
X95730.tblastn - program outputIt is probably not necessary to perform these searches with all sequences in defensin.gen. Where two query sequences are closely-related, both will give roughly the same results. However, it is worth sampling as broad a taxonomic range as possible. Both of the previous test sequences came from dicotyledonous plants. Therefore, we'll show on more example, using a defensin-like sequence from the monocot wheat (Triticum aestivum).
X95730.tblastn.acc - names of hits
Output:
AB089942.tblastn - program output
AB089942.tblastn.acc - names of hits
cat *.acc > temp1to create a temporary file called temp1, containing all accession numbers. Next, the numbers need to be sorted to make it easier to eliminate duplicate hits found in more than one search
sort < temp1 > temp2
Finally, duplicate lines are filtered out using the uniq command:
uniq < temp2 > all.accSee the manual pages for each command to get a better idea of what they do (eg. man sort, man uniq).
cat *.acc | sort | uniq > all.accAs a check, we can use the wc command to tell us how many lines (ie. accession numbers)
Note that the lengths of the files other than all.acc add up to 496, and all.acc is only 249. This is because the tblastn searches will often find the same sequences, so there is some redundancy in the .acc files.
wc -l *.acc
189 AB089942.tblastn.acc
249 all.acc
83 AY313169.tblastn.acc
24 temp.acc
200 X95730.tblastn.acc
745 total



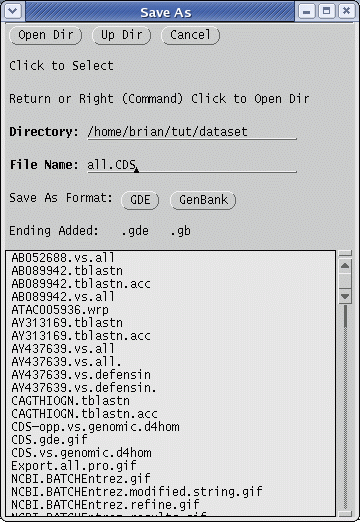
| Save
the sequences in this file by choosing File
--> Save As, and
call
the file all.CDS.gde. Make sure the file is saved in GDE format, so
that GDE can read it. (The .gde extension will be added automatically.) |
 |
As more and more large genomic
fragments are entered into GenBank,
FASTA searches will find sequences that they match only a small part
of the total fragment. That is, the gene you are using as a query
sequence will be only one of many genes on the fragment. Thus,
FEATURES will generate all protein coding sequences (CDS) for all genes
on each fragment. The
16 coding sequences for AC005936 are highlighted above.
We can create a small
database of all proteins translated from the CDS sequences, and then
search with FASTA to identify which encode defensins.
As was done previously, translate all CDS sequences to proteins by
choosing Edit --> Select All
and
using DNA/RNA --> ribosome.
(Note: DNA/RNA --> Translate
would
also work, but it tacks on numbers to the sequence names, indicating
reading frame. In the multiple alignment tutorial, these extra numbers
could cause some confusion, so avoid Translate, for now.) Choose Output to new GDE window.
| In
the new window, select all sequences (Edit
-- Select All), and choose File
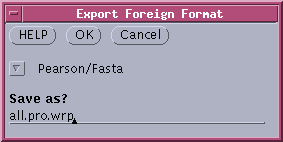
--> Export foreign format. Choose "Pearson/Fasta" format,
and call the file all.pro.wrp.
The file will
contain all of the protein sequences. |
 |
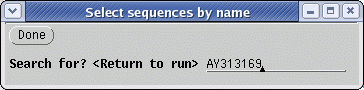
We can use the same three defensin
sequences as used in the original
database search to search all.pro.wrp. To start, find the AY313169
amino acid sequence using Edit -->
Select by Name
Next, choose Database
--> Fasta (protein vs.
protein database).
| This
time, instead of searching GenBank,
search the data set in all.pro.wrp. |
|
| Use
ssearch, which constructs a rigorous Smith/Waterman alignment for each
pairwise comparison. |
 |
| Set the E value, which is the
cut off for listing hits. In this case, hits will only be
included in the output if they have a probability of matching by random
chance of less than 0.001. |
 |
 By default,
the FASTA programs calculate statistics assuming that significant hits
will occur with only a very small fraction of sequences in the
database. This assumption is invalid with the all.pro.wrp dataset.
Setting the -z 11 option tell FASTA to calculate E values for a
population in which most sequences are closely-related. By default,
the FASTA programs calculate statistics assuming that significant hits
will occur with only a very small fraction of sequences in the
database. This assumption is invalid with the all.pro.wrp dataset.
Setting the -z 11 option tell FASTA to calculate E values for a
population in which most sequences are closely-related. If you do not set this option, you will miss most of the homologous coding sequences! |
|
| Send
output to a file. |
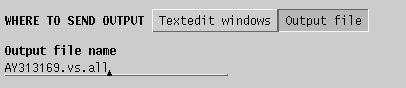 |
Repeat
the process for the other
two sequences. The ssearch results in the
three output files tell us which CDS sequences to keep, and which to
delete from the dataset. For this purpose, it would be useful to have a
list of significant matches, which can be created as follows. First use
a text editor to create an empty file
called all.hits. Now, copy the summary lines, such as
AY437639:CDS1 74 bp ( 74) 525 131.0 1.1e-34
NM_126272:CDS1 78 bp ( 78) 220 56.9 2.5e-12
AJ843264:CDS1 73 bp ( 73) 212 54.8 1e-11
NM_125761:CDS1 74 bp ( 74) 204 52.8 3.9e-11
AF322914:CDS1 78 bp ( 78) 203 52.7 4.4e-11
NM_126271:CDS1 78 bp ( 78) 199 51.8 8.6e-11
NM_104788:CDS1 77 bp ( 77) 193 50.3 2.4e-10
NM_126273:CDS1 78 bp ( 78) 192 50.1 2.8e-10
AF442388:CDS1 79 bp ( 79) 191 49.9 3.3e-10
AY498565:CDS1 79 bp ( 79) 191 49.9 3.3e-10
AY078426:CDS1 80 bp ( 80) 190 49.6 3.8e-10
into all.hits. Save the
file, and then sort the results for readabiility:
cat all.hits | cut
-f1 -d" " | sort | uniq > all.hits.sort
(Note that the cut
command extracts just the names of the sequences.)
Finally, we can use this file to
extract only those sequences whose names appear in all.hits.sort into a
new dataset. This file contains all the CDS sequences in our dataset,
not just those coding for defensin proteins.
Open up a new GDE
window and read in all.CDS.gde. Choose Edit --> Select All to select
all sequences.
Now, we'll read in the names of
the hits and extract those sequences into a new window. Choose Edit --> Extract subset.
Under NAMES/ACCESSION #'s, choose File
of Names/Acc.#'s. Enter the all.hits.sort on the line below.
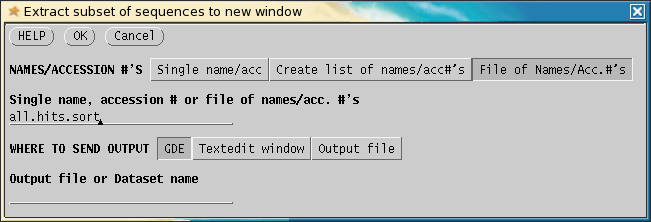
Click on OK. GDE will run BLExtractSubset.py
and send the results to a new GDE window. The sequences will appear in
the order that they are listed in all.hits.sort. Now, only defensin
sequences should be in this file. Save these sequences in File --> Save As, under the name
defensin.CDS.gde. Make sure to click on the GDE
button in the Save As menu to tell GDE to write the file in .gde format.
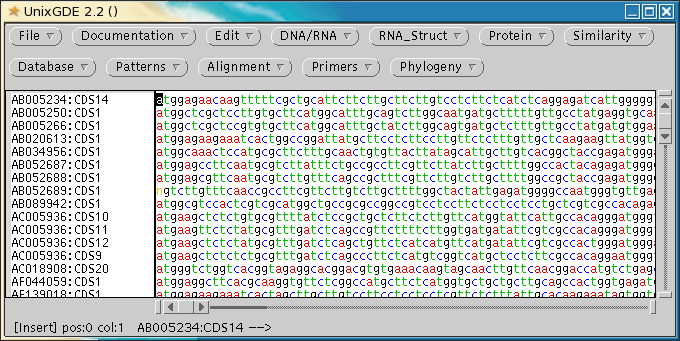
This illustrates an
important point regarding FASTA searches. Most database searches will
only find the BEST alignment between a query sequence and a
sequence in the database. In the case
where several homologous genes are present in a single database
entry, only the best match with the query sequence is likely to be
reported, and the others ignored! If we hadn't been
careful, we would have missed 3 out of the 4 defensin-related genes
in AC005936.
|
The dataset is complete! It is now ready for
creating multiple sequence alignments, and from there, for phylogenetic
analysis. |
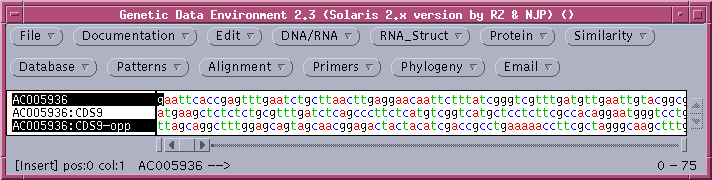
The comparison of the forward strand of AC005936 with the opposite strand of CDS9 shows no compelling similarities, which may not be surprising considering the fact that CDS9-12 were all on the forward strand, according to the Features Table.
The clustering of members of the defensin gene family on one strand, within several kilobases is probably evidence that these genes have been duplicated by unequal crossing over in recent evolutionary time.