
Welcome to the Monthly Mystery Spectrogram webzone. These pages are Rob Hagiwara's professional web-space. For personal musings, please see Rob's blog.

This is the How To page of the mystery spectrogram webzone. Contents for this page:
May 2009: fixed broken rollovers, miscellaneous text cleaning
September 2007: updated menus and navigation
May 2006: Commentary about stuff that I plan to change, or would like some in put on, is interspersed throughout this version of the page, in this goofy text. Depending on your browser, I think this is rendered in colo(u)r. General stuff changing throughout:
The same way you get to Carnegie Hall: practice, practice, practice!
First, read the chapter on acoustic analysis in Ladefoged's A Course in Phonetics, or better yet take a course based on Ladefoged's Elements of Acoustic Phonetics or Johnson's Acoustic and Auditory Phonetics. Or you can just read this summary, but bear in mind there's going to be a lot left out, especially in the 'why' realm. Then (as usual) learn by doing!
The goal of this page is to provide just enough basic information for the novice to begin, perhaps with some guidance, the process of decoding the monthly mystery spectrogram. This page is not intended to be the last word in spectrographic analysis in general, nor even the last word on spectrogram reading. However, reasoning your way through a mystery spectrogram is very instructive, especially in relating acoustic events with (presumed) articulatory ones. That is, in relating physical sounds with speech production.
If you're reading this, I assume you are familiar with basic articulatory phonetics, phonetic transcription, the International Phonetic Alphabet, and the surface phonology of 'general' North American English (i.e. phonemes and basic contrasts, and major allophonic variation such as vowel nasalization, nasal place assimilation, and so forth). I try to keep in mind that I have an international audience, but there are some details I just take to be 'given' for English. Someday if we do spectrograms of other languages, we'll have to adjust.
I really recommend that beginners find someone to discuss spectrographic issues with. If you're doing spectrograms as part of a class, form a study group. If you're a 'civilian', form a club. Or something. I'm toying with the idea of starting a Yahoo group or something for us to do some discussions as 'community'. Strong opinions anyone? Unfortunately, I don't have time to answer in detail every e-mail I receive about specific spectrograms or sounds or features, but if you have a general question or suggestions, please feel free to contact me.
Please note: My style sheet calls for this page to be rendered in either Victor Gaultney's Gentium font, or in SIL's SILDoulosIPAUnicode. These fonts are (in my opinion) the best available freeware fonts for IPA-ing in Unicode for the web. Please see my list of currently supported fonts for justification and links to download these fonts.
A sound spectrogram (or sonogram) is a visual representation of an acoustic signal. To oversimplify things a fair amount, a Fast Fourier transform is applied to an electronically recorded sound. This analysis essentially separates the frequencies and amplitudes of its component simplex waves. The result can then be displayed visually, with degrees of amplitude (represented light-to-dark, as in white=no energy, black=lots of energy), at various frequencies (usually on the vertical axis) by time (horizontal).
Depending on the size of the Fourier analysis window, different levels of frequency/time resolution are achieved. A long window resolves frequency at the expense of time—the result is a narrow band spectrogram, which reveals individual harmonics (component frequencies), but smears together adjacent 'moments'. If a short analysis window is used, adjacent harmonics are smeared together, but with better time resolution. The result is a wide band spectrogram in which individual pitch periods appear as vertical lines (or striations), with formant structure. Generally, wide band spectrograms are used in spectrogram reading because they give us more information about what's going on in the vocal tract, for reasons which should become clear as we go.
We often talk about speech in terms of source-filter theory. Put simply, we can view the vocal tract like a musical instrument. There's a part that actually makes sound (e.g. the string, the reed, or the vocal folds), and the part that 'shapes' the sound (e.g. the body of the violin, the horn of the clarinet, or the supralaryngeal articulators). In speech, this source of sound is provided primarily by the vibration of the vocal folds. From a mathematical standpoint, vocal fold vibration is complex, consisting of both a fundamental frequency and harmonics. Because the harmonics always occur as integral multiples of the fundamental (x1, x2, x3, etc.—which phenomenon was mathematically proven by Fourier, hence "Fourier's Theorem" and "Fourier Transform"), it turns out that the sensation of pitch of voice is correlated to both the fundamental frequency, and the distance between harmonics.
The point is that vocal source isn't just one frequency, but many frequencies ranging from the fundamental all the way up to infinity, in principle, in integral multiples. Just as white light is many frequencies of light all mixed up together, so is the vocal source a spectrum of acoustic energy, going from low frequencies (the fundamental) to high frequencies. In principle, there's some energy at all frequencies (although unless you're talking about an integral multiple of the fundamental, the amount will be zero).
The energy provided by the source is then filtered or shaped by the body of the instrument. In essence, the filter sifts the energy of some harmonics out (or at least down) while boosting others. The analogy to light again is apt. If you pass a white light through a red filter, you end up removing (or lessening) the energy at the blue end of the spectrum, while leaving the red end of the spectrum untouched. Depending on the filter, you might pass a band of energy in the red end and a band of energy in the green band, and something else. The 'color' of light that results will be different depending on which frequencies exactly get passed, and which ones get filtered.
In speech, these different tonal qualities change depending on vocal tract configuration. What makes an [i] sound like an [i] is not something to do with the source, but the shape of the filter, boosting some frequencies and damping others, depending on the shape of the vocal tract. So the 'quality' of the vowel depends on the frequencies being passed through the acoustic filter (the vocal tract), just as the 'color' of light depends on the frequencies being passed through the light filter.
So, we can manipulate source characteristics (the relative frequency and amplitude of the fundamental—and some properties of some of the harmonics) at the larynx independently of filter characteristics (vocal tract shape). < a href="#figfilter">Figure 1, is a spectrogram of me saying [ i ɑ i ɑ ] (i.e. "ee ah ee ah") continuously on a steady pitch. On the left, a wide band spectrogram shows the formants (darker bands running horizontally across the spectrogram) changing rapidly as my vocal tract moves between vowel configurations. (Take a moment to notice that the wide band spectrogram is striated, and the horizontal formants are 'overlaid' over the basic pattern of vertical striationsn.) On the right, a narrow band spectrogram reveals that the harmonics—the complex frequencies provided by the source—are steady, i.e. the pitch throughout is flat. Because some harmonics are stronger than others at any given moment, you can make out the formant structure even in the narrow band spectrogram. The filter function (the formant structure) is superimposed over the source structure.
If you're still not sure what I mean by 'band' or 'formant', pass your mouse
cursor over the figure. I've marked the center frequency, more or less, of each
visible formant in the figure. Look for the  in captions of spectrograms for extra information like this.
Depending on your hardware/software configuration,
you should also be able to play the audio clip, by pressing the 'play' button in the
figure caption.
in captions of spectrograms for extra information like this.
Depending on your hardware/software configuration,
you should also be able to play the audio clip, by pressing the 'play' button in the
figure caption.

Figure 1. wide band (left) and narrow band (right) spectrograms,
illustrating changing vowel quality with level pitch.
The other side of the source-filter coin is that you can vary the pitch (source) while keeping the the same filter. Figure 2 shows wide and narrow band spectrograms of me going [aː], but wildly moving my voice up and down. The formants stay steady in the wide band spectrogram, but the spacing between the harmonics changes as the pitch does. (Harmonics are always evenly spaced, so the higher the fundamental frequency —the pitch of my voice—the further apart the harmonics will be.)

Figure 2. wide band (left) and (narrow band) spectrgrams of me saying [aː],
but with wild pitch changes.
I like to divide the kinds of sources in speech into three categories: periodic voicing (or vibration of the vocal folds), non-voicing (which most people don't consider, but I like to distinguish it from my third category), and aperiodic noise (which results from turbulent airflow).
Voicing is represented on a wide band spectrogram by vertical striations, especially in the lowest frequencies. Each vertical 'line' represents a single pulse of the vocal folds, a single puff of air moving through the glottis. We sometimes refer to a 'voicing bar', i.e. a row of striated energy in the very low frequencies, corresponding to the energy in the first and second harmonics (typically the strongest harmonics in speech). For men, this is about 100-150 Hz, for women it can be anywhere between 150-250 Hz, and of course there's lots of variation both within and between individuals. In a narrow band spectrogram, voicing results in harmonics, with again the lowest one or two being the strongest.
Non-voicing is basically silence, and doesn't show up as anything in a spectrogram. So while there isn't a lot going on during silence that we can see in a spectrogram, we can still tell the difference between voiced sounds (with a striated voicing bar) and voiceless sounds (without). And usually there's still air moving through the vocal tract, which can provide an alternative source of acoustic energy, via turbulence or 'noise'.
On the other hand, it's worth distinguishing several glottal states that lead to non-voicing. Typically, active devoicing, results from vocal fold abduction. The vocal folds are held wide apart and thus movement of air through the glottis doesn't cause the folds to vibrate. If the vocal folds are tightly adducted (brought together in the midline) and stiffened, the result is no air movement through the glottis, due to glottal closure. Ideally, this is how a 'glottal stop' is produced. Finally, the vocal folds may be in 'voicing position', loosely adducted and relatively slack. But if there is insufficient pressure below the glottis (or too much above the glottis) the air movement through the glottis won't be enough to drive vibration, and passive devoicing occurs.
Noise is random (rather than striated or harmonically organized) energy, and usually results from friction. In speech this friction is of two types. There's the turbulence generated by the air as it moves past the walls of the vocal tract, usually called 'channel frication'. This is just 'drag', resistance to the free flow of air. If the air is blown against (instead of across) an object, you get even more turbulence, which we sometimes call 'obstacle frication'. For instance, when we make an [s], a jet of air is blown against the front teeth—the sudden displacement results in a lot of turbulence, and therefore noise. In spectrograms, noise is 'snowy'. The energy is placed in frequency and amplitude more randomly rather than being organized neatly into striations or clear bands. (Not to say they're aren't or can't be bands. They're just usually don't have 'edges' to the degree that formants do. Or may.)
We'll return to voicing and voicelessness below, after we deal with vowels.
A formant is a dark band on a wide band spectrogram, which corresponds to a vocal tract resonance. Technically, it represents a set of adjacent harmonics which are boosted by a resonance in some part of the vocal tract. Thus, different vocal tract shapes will produce different formant patterns, regardless of what the source is doing. Consider the spectrograms in Figure 3, which represents the simplex vowels of American English (at least in my voice). In the top row are "beed, bid, bade, bed, bad" (i.e. [bid] [bɪd] [beɪd] [bɛd] [bæd]). Notice that as the vowels get lower in the 'vowel space', the first formant (formants are numbered from the bottom up) goes up. In the bottom row, the vowels raise from "bod" to "booed"—the F1 starts relatively high, and goes down indicating that the vowels start low and move toward high. The first formant correlates (inversely) to height (or directly to openness) of the vocal tract.
Now look at the next formant, F2. Notice that the back, round vowels have a very low F2. Notice that the vowel with the highest F2 is [i], which is the frontmost of the front vowels. F2 corresponds to backness and/or rounding, with fronter/unround vowels having higher F2s than backer/rounder vowels. It's actually much more complicated than that, but that will do for the beginner. If you're picky about facts or the math, take a class in acoustic phonetics.
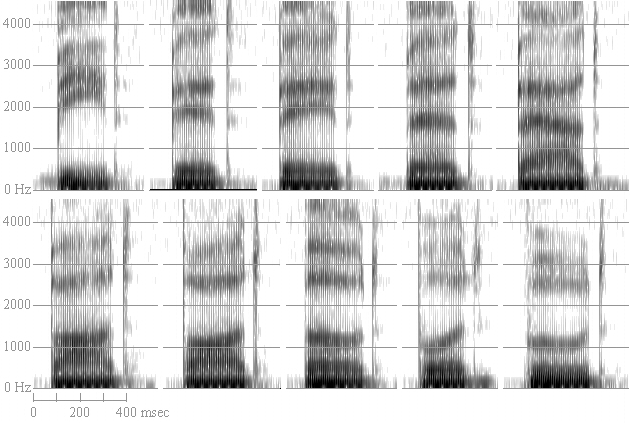
Figure 3. Wide band spectrograms of the vowels of American English in a
/b__d/ context.
Top row, left to right: [i, ɪ, eɪ, ɛ, æ].
Bottom row, left to right: [ɑ, ɔ, o, ʊ, u].
There are a variety of studies showing various acoustic correlates of vowel quality, among them formant frequency, formant movement, and vowel duration. Formant frequency (and movement) are probably the most important. So we can plot vowels in an F1xF2 vowel space, where F1 corresponds (inversely) to height, and F2 corresponds (inversely) to backness and we'll end up with something like the standard 'articulatory' vowel space.
Note that some of the vowels in Figure 3 ([eɪ] and [ʊ] especially) show more movement during the vowel (beyond just the transitions). Whether that makes them diphthongs (or should be represented like diphthongs) I'll leave for somebody else to argue. But before we get too far, what would you imagine an [aɪ] or [aɪ] diphthong would look like?
It's worth pointing out now that all the formants show consonant transitions at the edges. Remember that the frequency of any given formant has to do with the size and shape of the vocal tract—as the vocal tract changes shape, so do the formants change frequency. So the way the formants move into and out of consonant closures and vowel 'targets', is an important source of information about how the articulators are moving.
Plosives (oral stops) involve a total occlusion of the vocal tract, and thus a 'complete' filter, i.e. no resonances being contributed by the vocal tract. The result a period of silence in the spectrogram, known as a 'gap'. A voiced plosive may have a low-frequency voicing bar of striations, usually thought of as the sound of voicing being transmitted through the flesh of the vocal tract. However, due to passive devoicing, it may not. And due to perseverative voicing even a 'voiceless' plosive may show some vibration as the pressures equalize and before the vocal folds fully separate. But let's not get lost in too many details.
Generally we can think about the English plosives as occurring at three places of articulation—at the lips, behind the incisors, and at the velum (with some room to play around each). The bilabial plosives, [p] and [b] are articulated with the lower lip pressed against the upper lip. The coronal plosives [t,d] are made with the tongue blade pressing against the alveolar ridge (or thereabouts). [k] and [g] are described as 'dorsal' (meaning 'articulated with the tongue body') and 'velar' (meaning 'articulated against or toward the velum'), depending on your point of view. (I tend to use the 'dorsal' and 'velar' interchangeably, which is very bad. I use 'coronal' because it's more accurate than 'alveolar', in the sense that everybody uses their tongue blade (if not the apex) for [t,d], but not everybody uses only their alveolar ridge.)
That controversy aside, the thing to remember is that during a closure, there's no useful sound coming at you—there's basically silence. So while the gap tells you it's a plosive, the transitions into and out of the closure (i.e. in the surrounding vowels) are going to be the best source of information about place of articulation. Figure 4 contains spectrograms of me saying 'bab' 'dad' and 'gag'.
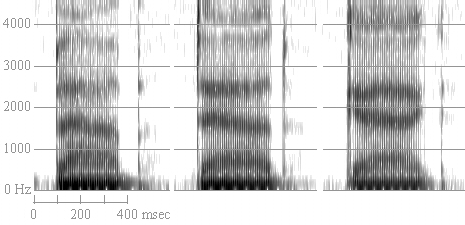
Figure 4. Spectrograms of "bab" "dad" and "gag".
.
There's no voicing during the initial closure of any of these plosives, confirming what your teachers have always told you: "voiced" plosives in English aren't always fully voiced during closure. Then suddenly, there's a burst of energy and the voicing begins, goes for a couple hundred milliseconds or so, followed by an abrupt loss of energy in the upper frequencies (above 400 Hz or so), followed by another burst of energy, and some noise. The first burst of energy is the release of the initial plosive. Notice the formants move or change following the burst, hold more or less steady during the middle of the vowel, and then move again into the following consonant. We know there's a closure because of the cessation of energy at most frequencies. The little blob of energy at the bottom is voicing, only transmitted through flesh rather than resonating in the vocal tract. Look closely, and you'll see that it's striated, but very weak. The final burst is the release of the final plosive, and the last bit of noise is basically just residual stuff echoing around the vocal tract.
Take a look at those formant transitions out of and into each plosive. Notice how the transitions in the F2 of 'bab' point down (i.e. the formant rises out of the plosive and falls into it again), where the F2 of 'gag' points up? Notice how in 'gag' the F2 and F3 start out and end close together? Notice how the F3 of 'dad' points slightly up at the plosives? Notice how the F1 always starts low, rises into the vowel, and then falls again.
Okay, these aren't necessarily the best examples, but basically, labials have downward pointing transitions (usually all visible formants, but especially F2 and F3), dorsals tend to have F2 and F3 transitions that 'pinch' together (hence 'velar pinch'), and the the F3 of coronals tends to point upward. The direction any transition points obviously is going to depend on the position of the formant for the vowel, so F2 of [t,d] might go up or down. A lot of people say coronal transitions point to about 1700 or 1800 Hz, but that's going to depend a lot on speaker-individual factors. Generally, I think of coronal F2 transitions as pointing upward unless the F2 of the vowel is particularly high.
Another thing to notice is the burst energy. Notice that the bursts for "dad" are darker (stronger) than the others. Notice also that they get darker in the higher frequencies than the lower. The energy of the bursts in "gag" are concentrated in the F2/F3 region, and less in the higher frequencies. The burst of [b] is sort of broad—across all frequencies, but concentrated in the lower frequencies, if anywhere. So bursts and transitions also give you information about place.
Figure 4 also illustrates that in initial position, phonemic /b, d, g/ tend to surface with no voicing during the closure, but a short voice onset time, i.e. as unaspirated [p, t, k]. In final position, they tend to surface as voiced, although there's room for variation here too.
Frankly, fricatives are not my favorite. They're acoustically and aerodynamically complex, not to mention phonologically and phonetically volatile. There's not a lot you can say about them without getting way too complicated, but I'll try.
Fricatives, by definition, involve an occlusion or obstruction in the vocal tract great enough to produce noise (frication). Frication noise is generated in two ways, either by blowing air against an object (obstacle frication) or moving air through a narrow channel into a relatively more open space (channel frication). In both cases, turbulence is created, but in the second case, it's turbulence caused by sudden 'freedom' to move sideways (Keith Johnson uses the terrific analogy of a road suddenly widening from two to four lanes, with a lot of sideways movement into the extra space), as opposed to air crashing around itself having bounced off an obstacle (Keith's freeway analogy of a road narrowing from four lanes to two works here, but I don't really want to think about serious sibilance in this respect....)
Sibilant fricatives involve a jet of air directed against the teeth. While there is some (channel) turbulence, the greater proportion of actual noise is created by bouncing the jet of air against the upper teeth. The result is very high amplitude noise. Non-sibilant fricatives are more likely 'pure' channel fricatives, particularly bilabial and labiodental fricatives, where there's not a lot of stuff in front to bounce the air off of.
In Figure 5, there are spectrograms of the fricatives, extracted from a nonce word ("uffah", "ussah", etc.).
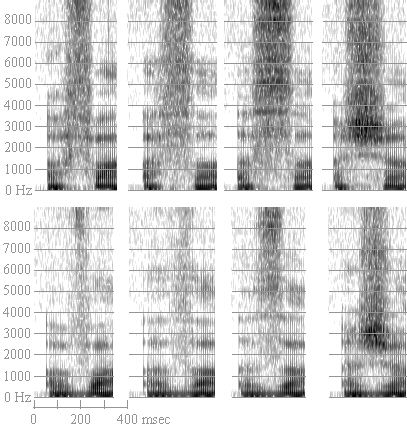
Figure 5: Top row, left to right: f, theta, s, esh. Bottom row, left to right:
v, eth, z, yogh.
Let's start with the sibilants "s" and "sh", in the upper right of Figure 5. They are by far the loudest fricatives. The darkest part of [s] noise is off the top of the spectrograms, even though these spectrograms have a greater frequency range than the others on this page. [s] is centered (darkest) above 8000 Hz. The postalveolar "sh", on the other hand, while almost as dark, has most of its energy concentrated in the F3-F4 range. Often, [s]s will have noise at all frequencies, where, as here, the noise for [ʃ] seems to drop off drastically below the peak (i.e. there's sometimes no noise below 1500 or 2000 Hz.) [z] and [ʒ] are distinguished from their voiceless counterparts by a) lesser amplitude of frication, b) shorter duration of frication and c) a voicing bar across the bottom. (Remember, however, that a lot of underlyingly voiced fricatives in English have voiceless allophones. What other cues are there to underlying voicing? Discuss.) Take a good look at the voicing bar through the fricatives in the bottom row. You may never see a fully voiced fricative from me again.
It's worth noting that F2 transitions are greater and higher with [ʃ] than with [s], and I seem to depress F4 slightly in [ʃ], but I don't know how consistent these markers are.
Labiodental and (inter)dental (nonsibilant) fricatives are notoriously difficult to distinguish, since they're made at about the same place in the vocal tract (i.e. the upper teeth), but with different active articulators. Having established (in a mystery spectrogram) that a fricative isn't loud enough to be a sibilant, you can sometimes tell from transitions whether it is labiodental or interdental—labiodental will have labial-looking transitions, interdentals might have slightly more coronal looking transitions. But that's poor consolation—often underlying labiodental and interdental fricatives don't have a lot of noise in the spectrogram at all, looking more like approximants. Sometimes, the lenite into approximants, or fortisize to stoppy-looking things. I hate fricatives.
Before moving on, we need to talk about [h]. [h] is always described as a glottal fricative, but since we know about channels and such, it's not clear where the noise actually comes from. Aspiration noise, which is also [h]-like, is produced by moving a whole lot of air through a very open glottis. I heard a paper once where they described the spectrum of [h]-noise as 'epiglottal', implying that the air is being directed at the epiglottis as an obstacle. Generally speaking, we don't think of the vocal cords moving together to form a 'channel' in [h], although breathy-voicing and voiced [h]s in English (as many intervocalic [h]s are produced) maybe be produced this way. So I don't know. What I do know about [h]s is that the noise is produced far enough back in the vocal tract that it excites all the forward cavities, so it's a lot like voicing in that respect. It's common to see 'formants' excited by noise rather than harmonics in spectrograms of [h]. Certainly, the noise will be concentrated in the formant regions. Compare the spectrograms in Figure 6.
![6. [h]](images/hnoise.jpg)
Figure 6. Spectrograms of "hee" "ha" and "who".
Notice how different the frication looks in each spectrogram. In "hee", the noise is concentrated in F2, F3 and higher, with every little in the 1000 Hz range. In "ha", in which F1 and F2 straddle 1000 Hz, the [h] noise is right down there. In "who", there is a lot less amplitude to the noise between 2000 and 3000 Hz, but there around F2 (around 1000 Hz) and lower, there's a great deal. You can even see F2 really clearly in the [h] of "who". So that's [h]. Don't ask me. It's not very common in my spectrograms....
Nasals have some formant stucture, but are better identified by the relative 'zeroes' or areas of little or no spectral energy. In Figure 7, the final nasals have identifiable formants that are lesser in amplitude than in the vowel, and the regions between them are blank. Nasality on vowels can result in broadening of the formant bandwidths (fuzzying the edges), and the introduction of zeroes in the vowel filter function. Nasals can be tough, and I hope to get someone who knows more about them than I do to say something else useful about them. You can sometimes tell from the frequency of the nasal formant and zero what place of articulation was, but it's usually easier to watch the formant transitions. (This is particularly true of initial nasals; final nasals I usually don't worry about--if you can figure out the rest of the word, there's only three possible nasals it could end with.) (Actually, being loose with the amount of information you actually have before you start trying to fit words to the spectrogram is one of the tricks to the whole operation.)
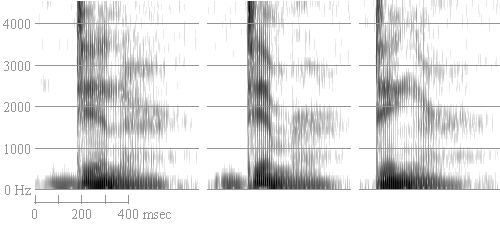
Figure 7. Spectrograms of "dinner", "dimmer", "dinger".
The real trick to recognizing nasals stops is a) formant structure, but b) relatively lower-than-vowel amplitude. Place of articulation can be determined by looking at the formant transitions (they are stops, after all), and sometimes, if you know the voice well, the formant/zero structure itself. Comparing the spectrograms above, we can see that 'dinger' (far right) has an F2/F3 'pinch'—the high F2 of [ɪ] moves up and seems to merge with the F3. In the nasal itself, the pole (nasal formant) is up in the neutral F3 region. 'Dinner' (middle) has a pole about 1500 Hz and a zero (a region of low amplitude) below it until you get down to about 500 Hz again. The pole for [m] in 'dimmer' is lower, closer to 1000 Hz, but there's still a zero between it and what we might call F1. Note also that the transitions moving into the [m] of dinner are all sharply down-pointing, even in the higher formants, a very strong clue to labiality, if you're lucky enough to see it.
In case you're not familiar with the term (generally attibuted to Ladefoged's Phonetic Study of West African Languages or as modified in Catford's Fundamental Problems in Phonetics), the approximants are non-vowel oral sonorants. In English, this amounts to /l, r, w, j/. They are characterized by formant structure (like vowels), but constrictions of about the degree of high vowels or slightly closer. Generally there's no friction associated with them, but the underlying approximants can have fricative allophones, just as fricative phonemes can occasionally have frictionless (i.e. approximant) allophones.
Canonically, the English approximants are those consonants which have obvious vowel allophones. The classic examples are the [j-i] pair and the [w-u] pair. I have argued that [ɹ] is basically vowel-like in structure, i.e. that syllabic /r/ is the most basic allophone, but there are those who disagree. Syllabic [l]s are all at least plausibly derived from underlying consonants, but I'm guessing that'll change in the next hundred years.
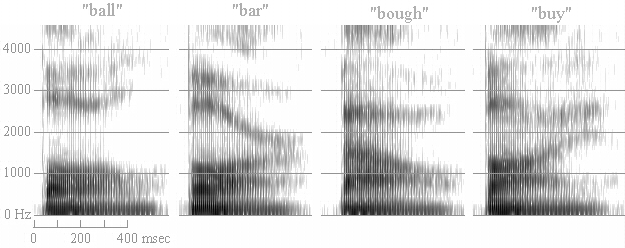
Figure 8. Spectrograms of 'ball', 'bar', 'bough', 'buy'.
In Figure 8, the approximants are presented in coda/final position, where the formant transitions are easiest to discern. Note that in all four words, the F1 is mid-to-high, indicating a more open constriction than with a typical high vowel. For /l/, the F2 is quite low, indicating a back tongue position—velarization of 'dark l' in English. The F3, on the other hand, is very high, higher than one ever sees unless the F2 is pushing it up out of the way. In "bar", the F3 comes way down, which is characteristics of [ɹ] in English. Compare the position of the F3 in "bar" with that in "bough" and "buy", where the F3 is relatively unaffected by the constriction.
In "bough", the F2 is very low, as the tongue position is relatively back and the lips are relatively rounded. Note that the this has no effect on F3, so let it be known that lip rounding has minimum effect on F3. Really. The next reviewer who brings up lip rounding without having some data to back it up is going to get it between the eyes. It's worth noting that the nuclear part of the diphthong is relatively front (as indicated by the F2 frequency in the first half of the diphthong) with the [aʊ] than in [aɪ]. In 'buy', the offglide has a clearly fronting (rising) F2.
One of the absolutely characteristic features of American English is "flapping". This is when an underlying /t/ (and sometimes /d/), is repaced by something which sounds a lot like a tapped /r/ in languages with tapped /r/s. I refer the reader to Susan Banner-Inouye's M.A. and Ph.D. theses on the phonological and phonetic interpretations of flappy/tappy things in general. But the easiest thing to do is compare them. The spectrograms in Figure 9 are of me reading "a toe", "a doe" and "otto", with an aspirated /t/, voiced /d/ and a flap respectively.
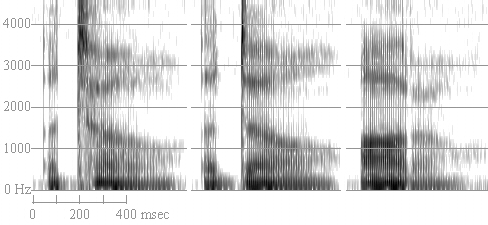
Figure 9. Spectrograms of "a toe", "a doe" and "otto".
Note that for both proper plosives, there's a longish period of relative silence (with a voicing bar in the case of /d/), on the order a 100 ms. The actual length varies a lot, but notice how short the 'closure' of the flapped case is in comparison. It's just a slight 'interruption' of the normal flow, a momentary thing, not something that looks very forceful or controlled. It doesn't even really have any transitions of its own. The interruption is something on the order of three pulses long, between 10 and 30 ms. That's basically the biggest thing. Sometimes they're longer, sometimes they're voiceless (occasionally even aspirated), but basically a flap will always be significantly shorter than a corresponding plosive.
Okay, so let's turn back to the proper plosives. Notice the aspiration following the /t/, and the short VOT following the /d/. Note the dying-off voicing during the /d/ closure, presumably due to a build up of supralaryngeal pressure. (Frankly, we're lucky to get any real voicing during the closure at all.)
(Other big allophonic categories I want to cover are nasalized vowels and rhoticized vowels, but I'm wondering how important they are at this level. Remember that this is a primer, not the be-all and end-all work on spectrogram reading. Also worth doing is some prosodic stuff, pitch and duration, amplitude and that kind of thing, as it relates to finding word and phrase boundaries in spectrogram reading. Comments?)
Well, obviously not. But it should be enough to get you started reading the monthly mystery spectrogram. We could go on and on about various things, but that's not the point right now. Remember, identify the features you can, try to guess some words, hypothesize, and then see if you can use your hypotheses to fill in some of the features you're unsure about. Do some lexical access, try some phrases, and see how well you do. Reading spectrograms, like transcription, and so many other things can be taught in a short time, but takes a long time and experience to learn. But then that's why we're here, right?
|
Robert Hagiwara, Ph.D. Dept. of Linguistics University of Manitoba Winnipeg, Manitoba CANADA R3T 5V5 |
How To - Research - Courses To the Lab - To the Department - To the University |
 |